OptaPlanner supports several optimization algorithms, but you're probably wondering which is the best one? Although some optimization algorithms generally perform better than others, it really depends on your problem domain. Most solver phases have parameters which can be tweaked. Those parameters can influence the results a lot, even though most solver phases work pretty well out-of-the-box.
Luckily, OptaPlanner includes a benchmarker, which allows you to play out different solver phases with different settings against each other, so you can pick the best configuration for your planning problem.
The benchmarker is in a separate artifact called optaplanner-benchmark.
If you use Maven, add a dependency in your pom.xml file:
<dependency>
<groupId>org.optaplanner</groupId>
<artifactId>optaplanner-benchmark</artifactId>
<version>...</version>
</dependency>
This is similar for Gradle, Ivy and Buildr. The version must be exactly the same as the
optaplanner-core version used.
If you use ANT, you've probably already copied the required jars from the download zip's
binaries directory.
You can build a PlannerBenchmark instance with the
XmlPlannerBenchmarkFactory. Configure it with a benchmark configuration xml file:
PlannerBenchmarkFactory plannerBenchmarkFactory = new XmlPlannerBenchmarkFactory(
"/org/optaplanner/examples/nqueens/benchmark/nqueensBenchmarkConfig.xml");
PlannerBenchmark plannerBenchmark = benchmarkFactory.buildPlannerBenchmark();
plannerBenchmark.benchmark();
A basic benchmark configuration file looks something like this:
<?xml version="1.0" encoding="UTF-8"?>
<plannerBenchmark>
<benchmarkDirectory>local/data/nqueens</benchmarkDirectory>
<!--<parallelBenchmarkCount>AUTO</parallelBenchmarkCount>-->
<warmUpSecondsSpend>30</warmUpSecondsSpend>
<inheritedSolverBenchmark>
<problemBenchmarks>
<xstreamAnnotatedClass>org.optaplanner.examples.nqueens.domain.NQueens</xstreamAnnotatedClass>
<inputSolutionFile>data/nqueens/unsolved/unsolvedNQueens32.xml</inputSolutionFile>
<inputSolutionFile>data/nqueens/unsolved/unsolvedNQueens64.xml</inputSolutionFile>
<problemStatisticType>BEST_SCORE</problemStatisticType>
</problemBenchmarks>
<solver>
<solutionClass>org.optaplanner.examples.nqueens.domain.NQueens</solutionClass>
<planningEntityClass>org.optaplanner.examples.nqueens.domain.Queen</planningEntityClass>
<scoreDirectorFactory>
<scoreDefinitionType>SIMPLE</scoreDefinitionType>
<scoreDrl>/org/optaplanner/examples/nqueens/solver/nQueensScoreRules.drl</scoreDrl>
</scoreDirectorFactory>
<termination>
<maximumSecondsSpend>20</maximumSecondsSpend>
</termination>
<constructionHeuristic>
<constructionHeuristicType>FIRST_FIT_DECREASING</constructionHeuristicType>
<forager>
<pickEarlyType>FIRST_NON_DETERIORATING_SCORE</pickEarlyType>
</forager>
</constructionHeuristic>
</solver>
</inheritedSolverBenchmark>
<solverBenchmark>
<name>Entity tabu</name>
<solver>
<localSearch>
<changeMoveSelector>
<selectionOrder>ORIGINAL</selectionOrder>
</changeMoveSelector>
<acceptor>
<entityTabuSize>5</entityTabuSize>
</acceptor>
<forager>
<pickEarlyType>NEVER</pickEarlyType>
</forager>
</localSearch>
</solver>
</solverBenchmark>
<solverBenchmark>
<name>Value tabu</name>
<solver>
<localSearch>
<changeMoveSelector>
<selectionOrder>ORIGINAL</selectionOrder>
</changeMoveSelector>
<acceptor>
<valueTabuSize>5</valueTabuSize>
</acceptor>
<forager>
<pickEarlyType>NEVER</pickEarlyType>
</forager>
</localSearch>
</solver>
</solverBenchmark>
<solverBenchmark>
<name>Move tabu</name>
<solver>
<localSearch>
<changeMoveSelector>
<selectionOrder>ORIGINAL</selectionOrder>
</changeMoveSelector>
<acceptor>
<moveTabuSize>5</moveTabuSize>
</acceptor>
<forager>
<pickEarlyType>NEVER</pickEarlyType>
</forager>
</localSearch>
</solver>
</solverBenchmark>
</plannerBenchmark>
This PlannerBenchmark will try 3 configurations (1 move tabu, 1 entity tabu and 1 value
tabu) on 2 data sets (32 and 64 queens), so it will run 6 solvers.
Every solverBenchmark element contains a solver configuration (for example with a local
search solver phase) and one or more inputSolutionFile elements. It will run the solver
configuration on each of those unsolved solution files. The element name is optional, because
it is generated if absent. The inputSolutionFile is read by a ProblemIO.
To lower verbosity, the common part of multiple solverBenchmark entities can be extracted
to the inheritedSolverBenchmark element. Yet, every element can still be overwritten per
solverBenchmark element. Note that inherited solver phases such as
<constructionHeuristic> or <localSearch> are not overwritten but
instead are added to the tail of the solver phases list.
You need to specify a benchmarkDirectory (relative to the working directory). A benchmark
report will be written in that directory.
Note
It's recommended that the benchmarkDirectory is a directory ignored for source control
and not cleaned by your build system. This way the generated files are not bloating your source control and they
aren't lost when doing a build. Usually that directory is called local.
The benchmarker needs to be able to read the input files to contain a Solution write
the best Solution of each benchmark to an output file. For that it uses a class that
implements the ProblemIO interface:
public interface ProblemIO {
String getFileExtension();
Solution read(File inputSolutionFile);
void write(Solution solution, File outputSolutionFile);
}
Warning
Your input files need to have been written with the same ProblemIO class as they are
being read by the benchmarker.
By default, a benchmarker uses a XStreamProblemIO instance to read and write
solutions.
You need to tell the benchmarker about your Solution class which is annotated with
XStream annotations:
<problemBenchmarks>
<xstreamAnnotatedClass>org.optaplanner.examples.nqueens.domain.NQueens</xstreamAnnotatedClass>
<inputSolutionFile>data/nqueens/unsolved/unsolvedNQueens32.xml</inputSolutionFile>
...
</problemBenchmarks>
Your input files need to have been written with a XStreamProblemIO instance, not just
any XStream instance, because the XStreamProblemIO uses a customized
XStream instance.
Warning
XStream (and XML in general) is a very verbose format. Reading or writing large datasets in this format
can cause an OutOfMemoryError and performance degradation.
Alternatively, you can implement your own ProblemIO implementation and configure it
with the problemIOClass element:
<problemBenchmarks>
<problemIOClass>org.optaplanner.examples.machinereassignment.persistence.MachineReassignmentProblemIO</problemIOClass>
<inputSolutionFile>data/machinereassignment/input/model_a1_1.txt</inputSolutionFile>
...
</problemBenchmarks>
Warning
A ProblemIO implementation must be thread-safe.
The best solution of each benchmark run can be written to the in the benchmarkDirectory.
By default, this is disabled, because the files are rarely used and considered bloat. Also, on large datasets,
writing the best solution of each single benchmark can take quite some time and memory (causing an
OutOfMemoryError), especially in a verbose format like XStream.
You can enable to write the output solution in the benchmarkDirectory with
writeOutputSolutionEnabled:
<problemBenchmarks>
...
<writeOutputSolutionEnabled>true</writeOutputSolutionEnabled>
...
</problemBenchmarks>
Without a warm up, the results of the first (or first few) benchmarks are not reliable, because they will have lost CPU time on HotSpot JIT compilation (and possibly DRL compilation too).
The avoid that distortion, the benchmarker can run some of the benchmarks for a specified amount of time, before running the real benchmarks. Generally, a warm up of 30 seconds suffices:
<plannerBenchmark>
...
<warmUpSecondsSpend>30</warmUpSecondsSpend>
...
</plannerBenchmark>
After the running a benchmark, a HTML report will be written in the benchmarkDirectory
with the filename index.html. Open it in your browser. It has a nice overview of your
benchmark including:
Summary statistics: graphs and tables
Problem statistics per
inputSolutionFileEach solver configuration (ranked): easy to copy and paste.
Benchmark information
The HTML report will use your default locale to format numbers. If you need to share the benchmark report
with people from another country, you might want to overwrite the benchmarkReportLocale:
<plannerBenchmark>
...
<benchmarkReportLocale>en_US</benchmarkReportLocale>
...
</plannerBenchmark>
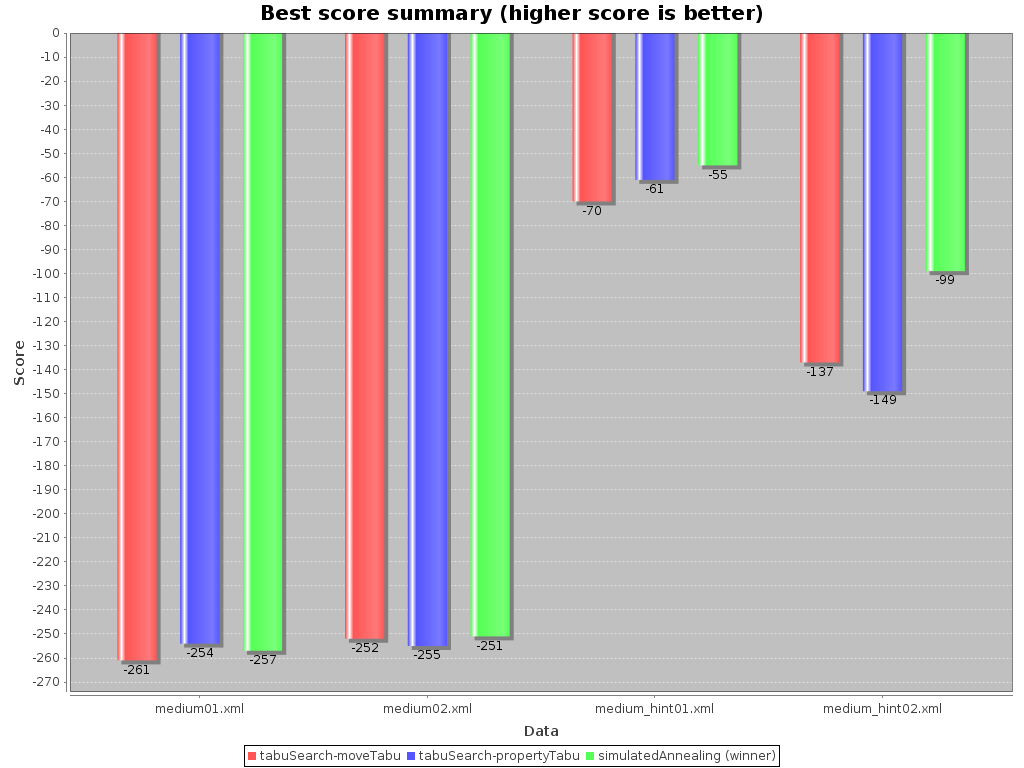
Shows the best score per inputSolutionFile for each solver configuration.
Useful for visualizing the best solver configuration.
Shows the best score per problem scale for each solver configuration.
Useful for visualizing the scalability of each solver configuration.
Shows the winning score difference score per inputSolutionFile for each solver
configuration. The winning score difference is the score difference with the score of the winning solver
configuration for that particular inputSolutionFile.
Useful for zooming in on the results of the best score summary.
Shows the return on investment (ROI) per inputSolutionFile for each solver
configuration if you'd upgrade from the worst solver configuration for that particular
inputSolutionFile.
Useful for visualizing the return on investment (ROI) to decision makers.
Shows the score calculation speed: the average calculation count per second per problem scale for each solver configuration.
Useful for comparing different score calculators and/or score rule implementations (presuming that the solver configurations do not differ otherwise). Also useful to measure the scalability cost of an extra constraint.
Shows the time spend per inputSolutionFile for each solver configuration. This is
pointless if it's benchmarking against a fixed time limit.
Useful for visualizing the performance of construction heuristics (presuming that no other solver phases are configured).
Shows the time spend per problem scale for each solver configuration. This is pointless if it's benchmarking against a fixed time limit.
Useful for extrapolating the scalability of construction heuristics (presuming that no other solver phases are configured).
Shows the best score per time spend for each solver configuration. This is pointless if it's benchmarking against a fixed time limit.
Useful for visualizing trade-off between the best score versus the time spend for construction heuristics (presuming that no other solver phases are configured).
The benchmarker supports outputting problem statistics as graphs and CSV (comma separated values) files to
the benchmarkDirectory.
To configure graph and CSV output of a statistic, just add a problemStatisticType
line:
<plannerBenchmark>
<benchmarkDirectory>local/data/nqueens/solved</benchmarkDirectory>
<inheritedSolverBenchmark>
<problemBenchmarks>
...
<problemStatisticType>BEST_SCORE</problemStatisticType>
<problemStatisticType>CALCULATE_COUNT_PER_SECOND</problemStatisticType>
</problemBenchmarks>
...
</inheritedSolverBenchmark>
...
</plannerBenchmark>
Multiple problemStatisticType elements are allowed. Some statistic types might
influence performance and benchmark results noticeably.
Note
These statistic per data set can slow down the solver noticeably, which can affect the benchmark results. That's why they are optional and not enabled by default.
The non-optional summary statistics cannot slow down the solver noticeably.
The following types are supported:
To see how the best score evolves over time, add:
<problemBenchmarks>
...
<problemStatisticType>BEST_SCORE</problemStatisticType>
</problemBenchmarks>
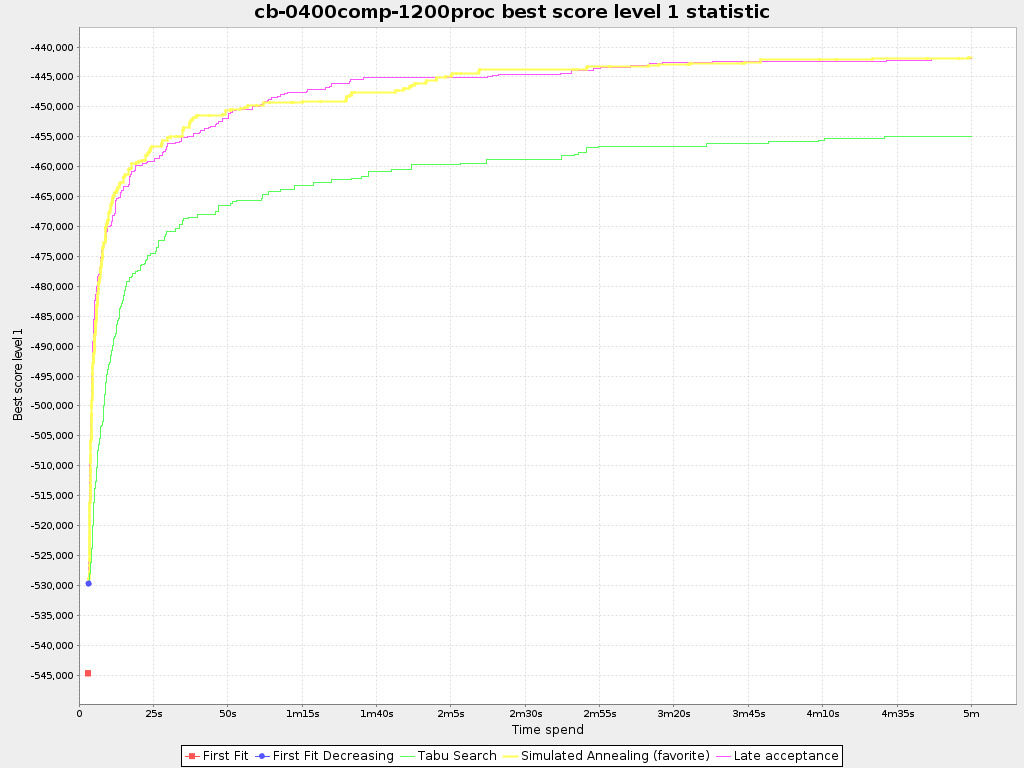
The best score over time statistic is very useful to detect abnormalities, such as a potential score trap.
Note
A time gradient based algorithm (such as Simulated Annealing) will have a different statistic if it's run with a different time limit configuration. That's because this Simulated Annealing implementation automatically determines its velocity based on the amount of time that can be spend. On the other hand, for the Tabu Search and Late Annealing, what you see is what you'd get.
To see how the step score evolves over time, add:
<problemBenchmarks>
...
<problemStatisticType>STEP_SCORE</problemStatisticType>
</problemBenchmarks>
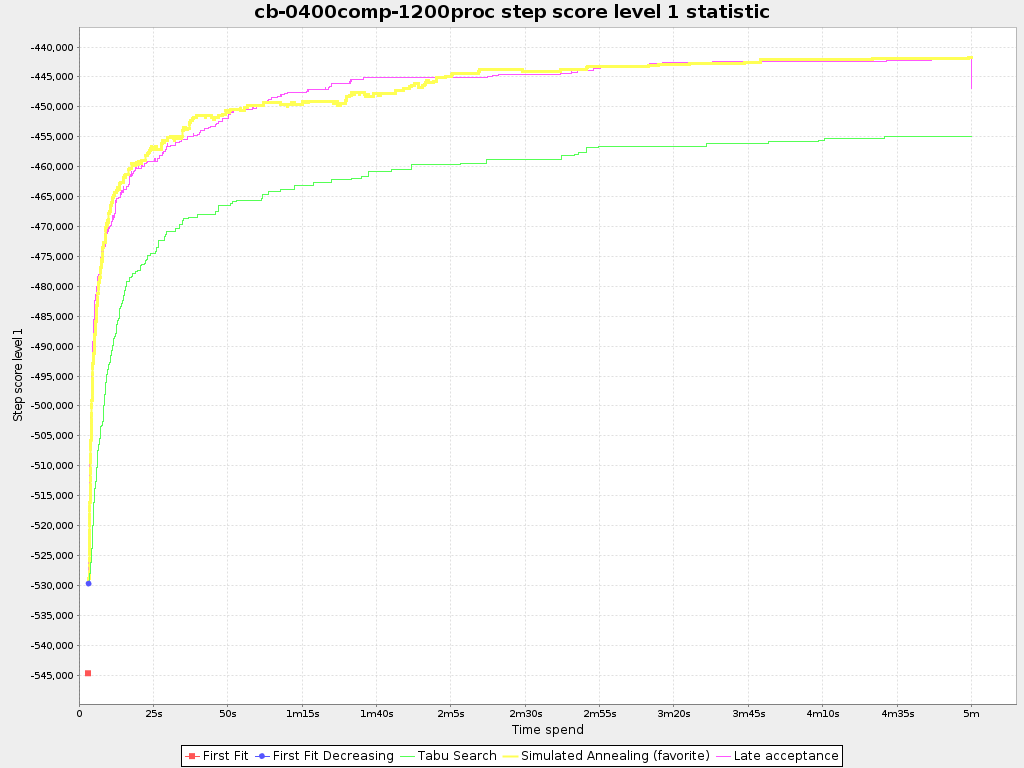
Compare the step score statistic with the best score statistic (especially on parts for which the best score flatlines). If it hits a local optima, the solver should take deteriorating steps to escape it. But it shouldn't deteriorate too much either.
Warning
The step score statistic has been seen to slow down the solver noticeably due to GC stress, especially for fast stepping algorithms (such as Simulated Annealing and Late Acceptance).
To see how fast the scores are calculated, add:
<problemBenchmarks>
...
<problemStatisticType>CALCULATE_COUNT_PER_SECOND</problemStatisticType>
</problemBenchmarks>
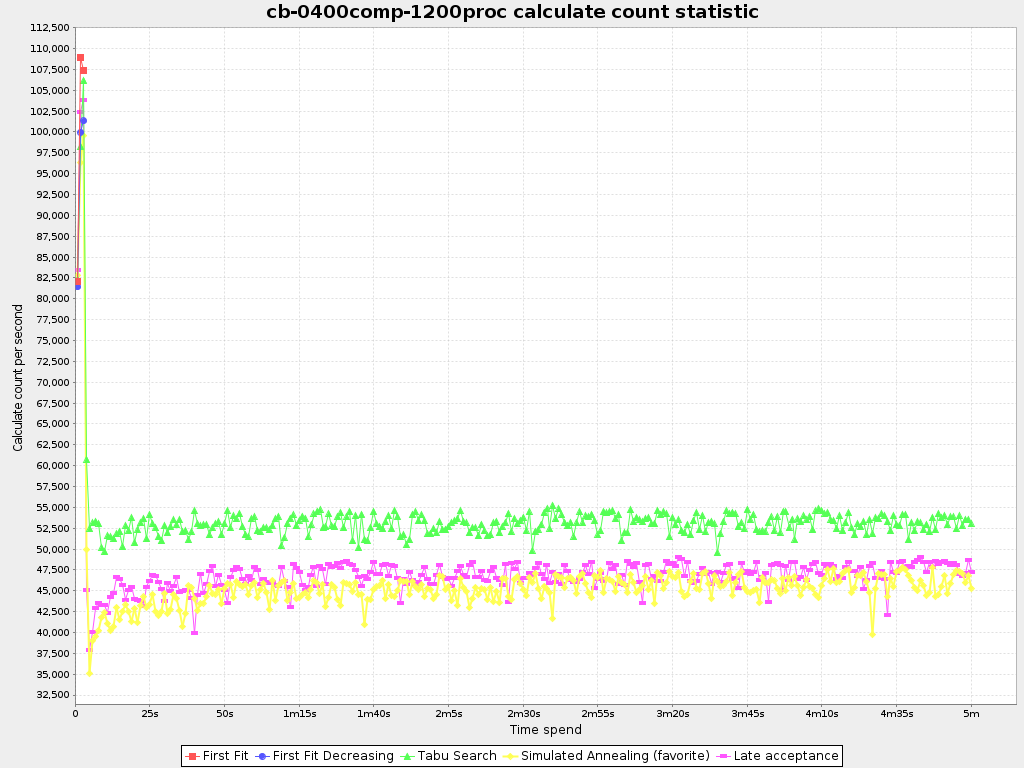
Note
The initial high calculate count is typical during solution initialization: it's far easier to calculate the score of a solution if only a handful planning entities have been initialized, than when all the planning entities are initialized.
After those few seconds of initialization, the calculate count is relatively stable, apart from an occasional stop-the-world garbage collector disruption.
To see how much each new best solution differs from the previous best solution, by counting the number of planning variables which have a different value (not including the variables that have changed multiple times but still end up with the same value), add:
<problemBenchmarks>
...
<problemStatisticType>BEST_SOLUTION_MUTATION</problemStatisticType>
</problemBenchmarks>
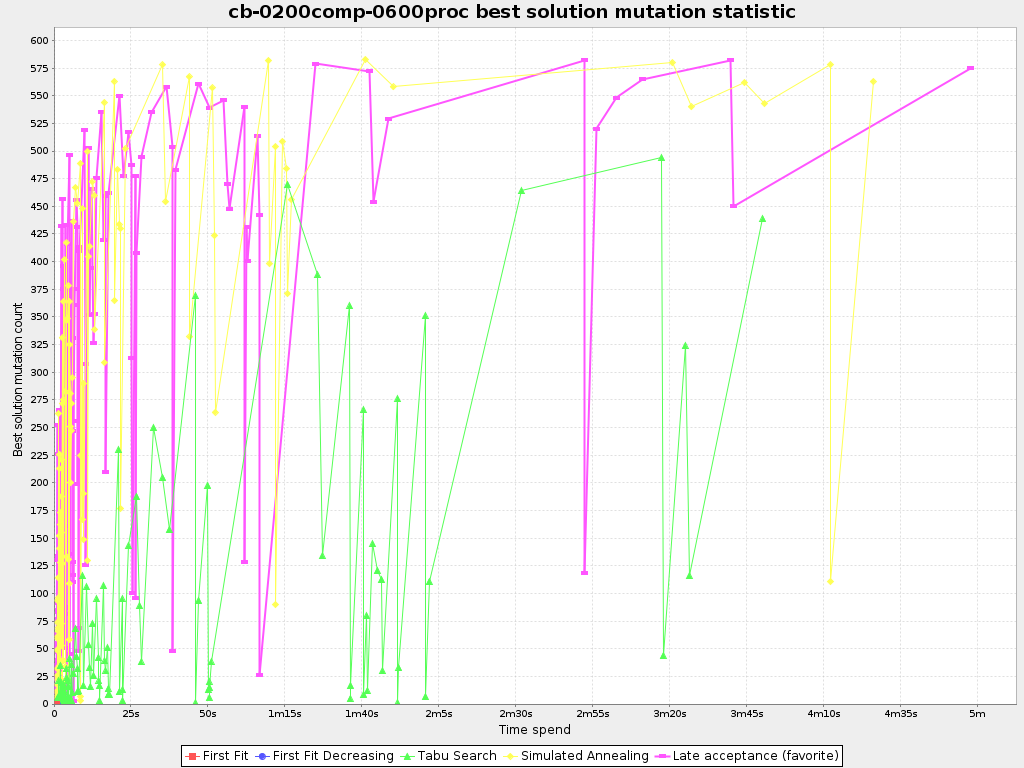
Use Tabu Search - an algorithm that behaves like a human - to get an estimation on how difficult it would be for a human to improve the previous best solution to that new best solution.
To see how the selected and accepted move count per step evolves over time, add:
<problemBenchmarks>
...
<problemStatisticType>MOVE_COUNT_PER_STEP</problemStatisticType>
</problemBenchmarks>
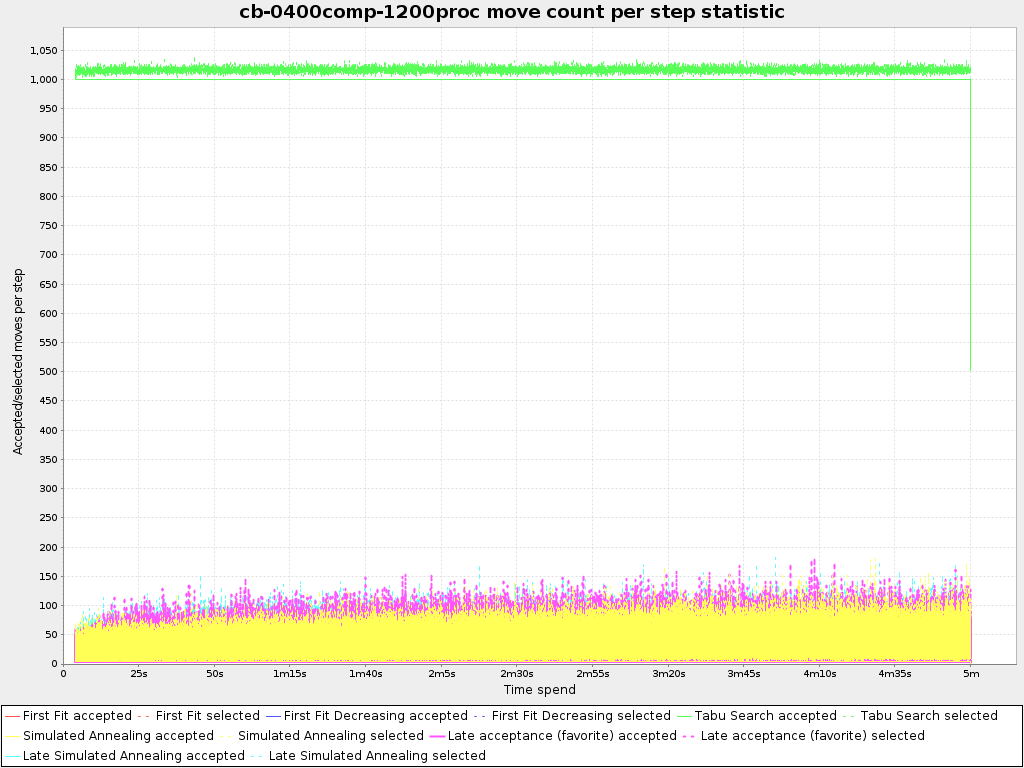
Warning
This statistic has been seen to slow down the solver noticeably due to GC stress, especially for fast stepping algorithms (such as Simulated Annealing and Late Acceptance).
The benchmark report automatically ranks the solvers. The Solver with rank
0 is called the favorite Solver: it performs best overall, but it might not
be the best on every problem. It's recommended to use that favorite Solver in
production.
However, there are different ways of ranking the solvers. Configure it like this:
<plannerBenchmark>
...
<solverBenchmarkRankingType>TOTAL_SCORE</solverBenchmarkRankingType>
...
</plannerBenchmark>
The following solverBenchmarkRankingTypes are supported:
TOTAL_SCORE(default): Maximize the overall score, so minimize the overall cost if all solutions would be executed.WORST_SCORE: Minimize the worst case scenario.TOTAL_RANKING: Maximize the overall ranking. Use this if your datasets differ greatly in size or difficulty, producing a difference inScoremagnitude.
You can also use a custom ranking, by implementing a Comparator:
<solverBenchmarkRankingComparatorClass>...TotalScoreSolverBenchmarkRankingComparator</solverBenchmarkRankingComparatorClass>
Or a weight factory:
<solverBenchmarkRankingWeightFactoryClass>...TotalRankSolverBenchmarkRankingWeightFactory</solverBenchmarkRankingWeightFactoryClass>
If you have multiple processors available on your computer, you can run multiple benchmarks in parallel on multiple threads to get your benchmarks results faster:
<plannerBenchmark>
...
<parallelBenchmarkCount>AUTO</parallelBenchmarkCount>
...
</plannerBenchmark>
Warning
Running too many benchmarks in parallel will affect the results of benchmarks negatively. Leave some processors unused for garbage collection and other processes.
We tweak parallelBenchmarkCount AUTO to maximize the reliability
and efficiency of the benchmark results.
The following parallelBenchmarkCounts are supported:
1(default): Run all benchmarks sequentially.AUTO: Let Planner decide how many benchmarks to run in parallel. This formula is based on experience. It's recommended to prefer this over the other parallel enabling options.Static number: The number of benchmarks to run in parallel.
<parallelBenchmarkCount>2</parallelBenchmarkCount>
JavaScript formula: Formula for the number of benchmarks to run in parallel. It can use the variable
availableProcessorCount. For example:<parallelBenchmarkCount>(availableProcessorCount / 2) + 1</parallelBenchmarkCount>
Note
The parallelBenchmarkCount is always limited to the number of available processors.
If it's higher, it will be automatically decreased.
Note
In the future, we will also support multi-JVM benchmarking. This feature is independent of multi-threaded solving or multi-JVM solving.
Matrix benchmarking is benchmarking a combination of value sets. For example: benchmark 4
entityTabuSize values (5, 7, 11 and
13) combined with 3 acceptedCountLimit values (500,
1000 and 2000), resulting in 12 solver configurations.
To reduce the verbosity of such a benchmark configuration, you can use a Freemarker template for the benchmark configuration instead:
<plannerBenchmark>
...
<inheritedSolverBenchmark>
...
</inheritedSolverBenchmark>
<#list [5, 7, 11, 13] as entityTabuSize>
<#list [500, 1000, 2000] as acceptedCountLimit>
<solverBenchmark>
<name>entityTabuSize ${entityTabuSize} acceptedCountLimit ${acceptedCountLimit}</name>
<solver>
<localSearch>
<unionMoveSelector>
<changeMoveSelector/>
<swapMoveSelector/>
</unionMoveSelector>
<acceptor>
<entityTabuSize>${entityTabuSize}</entityTabuSize>
</acceptor>
<forager>
<acceptedCountLimit>${acceptedCountLimit}</acceptedCountLimit>
</forager>
</localSearch>
</solver>
</solverBenchmark>
</#list>
</#list>
</plannerBenchmark>
And build it with the class FreemarkerXmlPlannerBenchmarkFactory:
PlannerBenchmarkFactory plannerBenchmarkFactory = new FreemarkerXmlPlannerBenchmarkFactory(
"/org/optaplanner/examples/cloudbalancing/benchmark/cloudBalancingBenchmarkConfigTemplate.xml.ftl");
PlannerBenchmark plannerBenchmark = benchmarkFactory.buildPlannerBenchmark();