Local Search starts from an initial solution and evolves that single solution into a mostly better and better solution. It uses a single search path of solutions, not a search tree. At each solution in this path it evaluates a number of moves on the solution and applies the most suitable move to take the step to the next solution. It does that for a high number of iterations until it's terminated (usually because its time has run out).
Local Search acts a lot like a human planner: it uses a single search path and moves facts around to find a good feasible solution. Therefore it's pretty natural to implement.
Local Search usually needs to start from an initialized solution, therefore it's usually required to configure a construction heuristic solver phase before it.
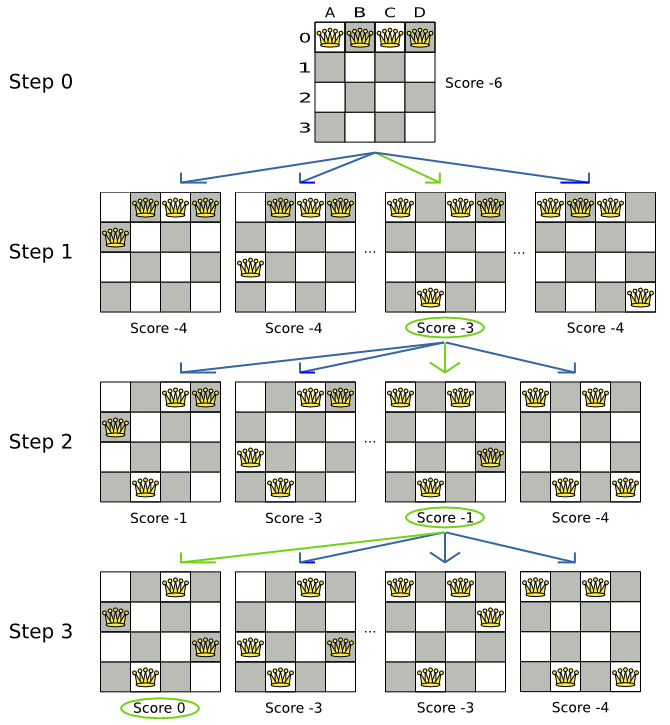
A step is the winning Move. The local search solver tries every move on the current
solution and picks the best accepted move as the step:
Because the move B0 to B3 has the highest score (-3), it is picked
as the next step. If multiple moves have the same highest score, one is picked randomly, in this case B0
to B3. Note that C0 to C3 (not shown) could also have been picked because it also
has the score -3.
The step is applied on the solution. From that new solution, the local search solver tries every move again, to decide the next step after that. It continually does this in a loop, and we get something like this:
Notice that the local search solver doesn't use a search tree, but a search path. The search path is highlighted by the green arrows. At each step it tries all possible moves, but unless it's the step, it doesn't investigate that solution further. This is one of the reasons why local search is very scalable.
As you can see, Local Search solves the 4 queens problem by starting with the starting solution and make the following steps sequentially:
B0 to B3
D0 to B2
A0 to B1
If we turn on debug logging for the category org.optaplanner, then
those steps are shown into the log:
INFO Solving started: time spent (0), best score (-6), random (JDK with seed 0). DEBUG LS step (0), time spent (20), score (-3), new best score (-3), accepted/selected move count (12/12), picked move (col1@row0 => row3). DEBUG LS step (1), time spent (31), score (-1), new best score (-1), accepted/selected move count (12/12), picked move (col0@row0 => row1). DEBUG LS step (2), time spent (40), score (0), new best score (0), accepted/selected move count (12/12), picked move (col3@row0 => row2). INFO Local Search phase (0) ended: step total (3), time spent (41), best score (0). INFO Solving ended: time spent (41), best score (0), average calculate count per second (1780).
Notice that the logging uses the toString() method of the Move
implementation: col1@row0 => row3.
A naive Local Search configuration solves the 4 queens problem in 3 steps, by evaluating only 37 possible solutions (3 steps with 12 moves each + 1 starting solution), which is only fraction of all 256 possible solutions. It solves 16 queens in 31 steps, by evaluating only 7441 out of 18446744073709551616 possible solutions. Note: with construction heuristics it's even a lot more efficient.
The local search solver decides the next step with the aid of 3 configurable components:
A
MoveSelectorwhich selects the possible moves of the current solution. See the chapter move and neighborhood selection.An
Acceptorwhich filters out unacceptable moves.A
Foragerwhich gathers accepted moves and picks the next step from them.
The solver phase configuration looks like this:
<localSearch>
<unionMoveSelector>
...
</unionMoveSelector>
<acceptor>
...
</acceptor>
<forager>
...
</forager>
</localSearch>
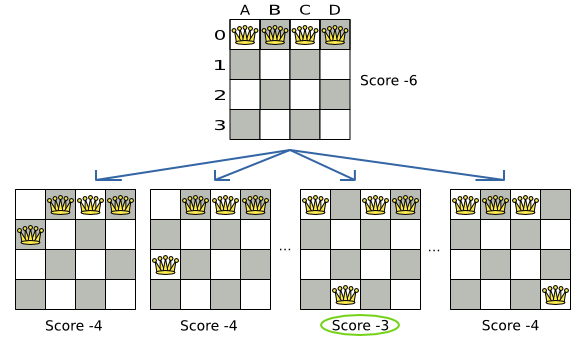
In the example below, the MoveSelector generated the moves shown with the blue lines, the
Acceptor accepted all of them and the Forager picked the move B0
to B3.
Turn on trace logging to show the decision making in the
log:
INFO Solver started: time spent (0), score (-6), new best score (-6), random (JDK with seed 0). TRACE Move index (0) not doable, ignoring move (col0@row0 => row0). TRACE Move index (1), score (-4), accepted (true), move (col0@row0 => row1). TRACE Move index (2), score (-4), accepted (true), move (col0@row0 => row2). TRACE Move index (3), score (-4), accepted (true), move (col0@row0 => row3). ... TRACE Move index (6), score (-3), accepted (true), move (col1@row0 => row3). ... TRACE Move index (9), score (-3), accepted (true), move (col2@row0 => row3). ... TRACE Move index (12), score (-4), accepted (true), move (col3@row0 => row3). DEBUG LS step (0), time spent (6), score (-3), new best score (-3), accepted/selected move count (12/12), picked move (col1@row0 => row3). ...
Because the last solution can degrade (for example in Tabu Search), the Solver remembers
the best solution it has encountered through the entire search path. Each time the current solution is better than
the last best solution, the current solution is cloned and referenced as the new best solution.
An Acceptor is used (together with a Forager) to active Tabu Search,
Simulated Annealing, Late Acceptance, ... For each move it checks whether it is accepted or not.
By changing a few lines of configuration, you can easily switch from Tabu Search to Simulated Annealing or Late Acceptance and back.
You can implement your own Acceptor, but the build-in acceptors should suffice for most
needs. You can also combine multiple acceptors.
A Forager gathers all accepted moves and picks the move which is the next step. Normally
it picks the accepted move with the highest score. If several accepted moves have the highest score, one is picked
randomly.
You can implement your own Forager, but the build-in forager should suffice for most
needs.
When there are many possible moves, it becomes inefficient to evaluate all of them at every step. To evaluate only a random subset of all the moves, use:
An
acceptedCountLimitinteger, which specifies how many accepted moves should be evaluated during each step. By default, all accepted moves are evaluated at every step.<forager>
<acceptedCountLimit>1000</acceptedCountLimit>
</forager>
Unlike the n queens problem, real world problems require the use of acceptedCountLimit.
Start from an acceptedCountLimit that takes a step in less then 2 seconds. Turn on INFO logging to see the step times. Use the Benchmarker to tweak the value.
Important
With a low acceptedCountLimit it is recommended to avoid using
selectionOrder SHUFFLED because the shuffling generates a random number for every element
in the selector, taking up a lot of time, but only a few elements are actually selected.
A forager can pick a move early during a step, ignoring subsequent selected moves. There are 3 pick early types for Local Search:
NEVER: A move is never picked early: all accepted moves are evaluated that the selection allows. This is the default.<forager>
<pickEarlyType>NEVER</pickEarlyType>
</forager>
FIRST_BEST_SCORE_IMPROVING: Pick the first accepted move that improves the best score. If none improve the best score, it behaves exactly like the pickEarlyType NEVER.<forager>
<pickEarlyType>FIRST_BEST_SCORE_IMPROVING</pickEarlyType>
</forager>
FIRST_LAST_STEP_SCORE_IMPROVING: Pick the first accepted move that improves the last step score. If none improve the last step score, it behaves exactly like the pickEarlyType NEVER.<forager>
<pickEarlyType>FIRST_LAST_STEP_SCORE_IMPROVING</pickEarlyType>
</forager>
Hill Climbing tries all selected moves and then takes the best move, which is the move which leads to the solution with the highest score. That best move is called the step move. From that new solution, it again tries all selected moves and takes the best move and continues like that iteratively. If multiple selected moves tie for the best move, one of them is randomly chosen as the best move.
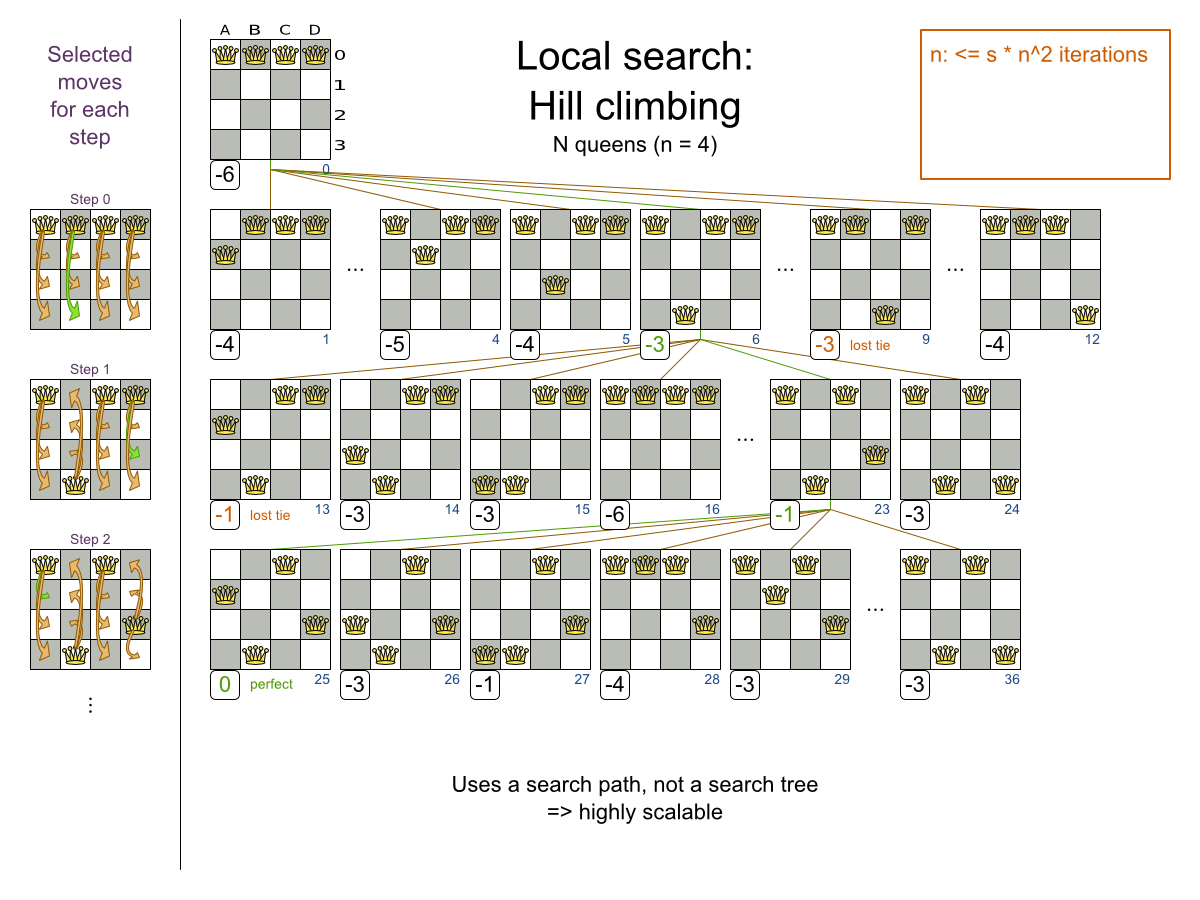
Notice that one a queen has moved, it can be moved again later. This is a good thing, because in an NP-complete problem it's impossible to predict what will be the optimal final value for a planning variable.
Hill Climbing always takes improving moves. This may seem like a good thing, but it's not: Hill Climbing can easily get stuck in a local optimum. This happens when it reaches a solution for which all the moves deteriorate the score. Even if it picks one of those moves, the next step might go back to the original solution and which case chasing it's own tail:
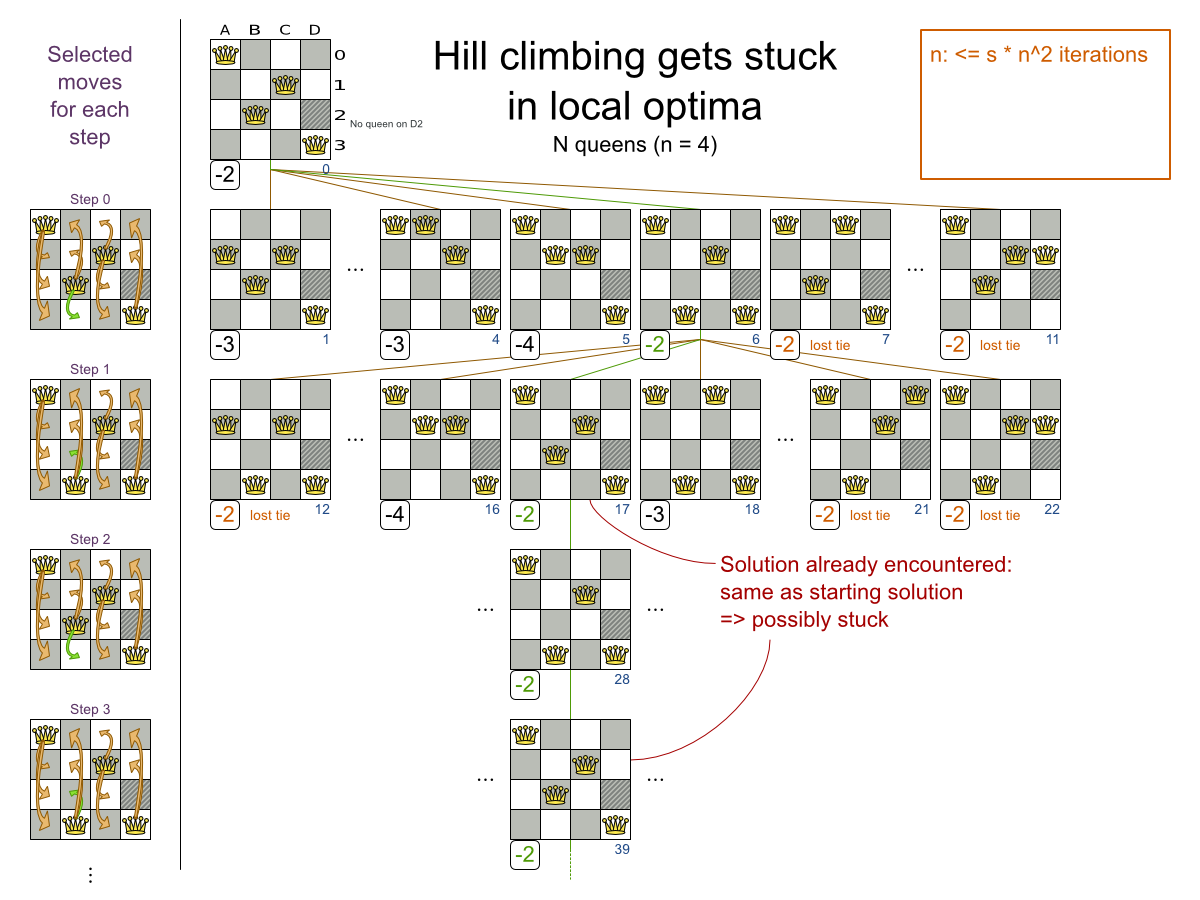
Improvements upon Hill Climbing (such as Tabu Search, Simulated Annealing and Late Acceptance) address the problem of being stuck in local optima. Therefore, it's recommend to never use Hill Climbing, unless you're absolutely sure there are no local optima in your planning problem.
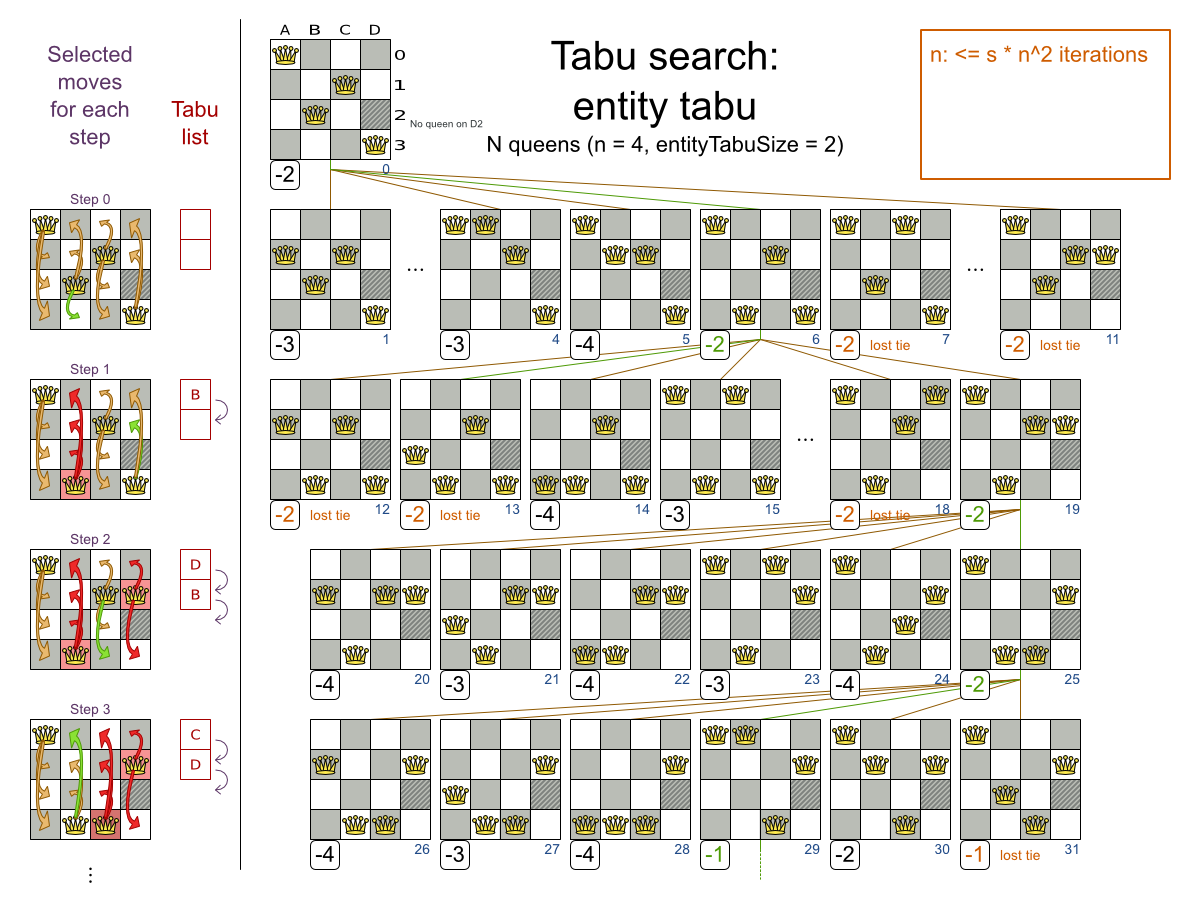
Tabu Search works like Hill Climbing, but it maintains a tabu list to avoid getting stuck in local optima. The tabu list holds recently used objects that are taboo to use for now. Moves that involve an object in the tabu list, are not accepted. The tabu list objects can be anything related to the move, such as the planning entity, planning value, move, solution, ... Here's an example with entity tabu for 4 queens, so the queens are put in the tabu list:
Scientific paper: Tabu Search - Part 1 and Part 2 by Fred Glover (1989 - 1990)
When Tabu Search takes steps it creates one or more tabu's. For a number of steps, it does not accept a move if that move breaks tabu. That number of steps is the tabu size.
<localSearch>
...
<acceptor>
<entityTabuSize>7</entityTabuSize>
</acceptor>
<forager>
<acceptedCountLimit>1000</acceptedCountLimit>
</forager>
</localSearch>
Important
A Tabu Search acceptor should be combined with a high acceptedCountLimit, such as
1000.
OptaPlanner implements several tabu types:
Planning entity tabu makes the planning entities of recent steps tabu. For example, for N queens it makes the recently moved queens tabu. It's recommended to start with this tabu type.
<acceptor>
<entityTabuSize>7</entityTabuSize>
</acceptor>
To avoid hard coding the tabu size, configure a tabu ratio, relative to the number of entities, for example 2%:
<acceptor>
<entityTabuRatio>0.02</entityTabuRatio>
</acceptor>
Planning value tabu makes the planning values of recent steps tabu. For example, for N queens it makes the recently moved to rows tabu.
<acceptor>
<valueTabuSize>7</valueTabuSize>
</acceptor>
To avoid hard coding the tabu size, configure a tabu ratio, relative to the number of values, for example 2%:
<acceptor>
<valueTabuRatio>0.02</valueTabuRatio>
</acceptor>
Move tabu makes recent steps tabu. It does not accept a move equal to one of those steps.
<acceptor>
<moveTabuSize>7</moveTabuSize>
</acceptor>
Undo move tabu makes the undo move of recent steps tabu.
<acceptor>
<undoMoveTabuSize>7</undoMoveTabuSize>
</acceptor>
Solution tabu makes recently visited solutions tabu. It does not accept a move that leads to one of those solutions. It requires that the
Solutionimplementsequals()andhashCode()properly. If you can spare the memory, don't be cheap on the tabu size.<acceptor>
<solutionTabuSize>1000</solutionTabuSize>
</acceptor>
For non-trivial cases, it's usually useless because the search space size makes it statistically almost impossible to reach the same solution twice.
You can even combine tabu types:
<acceptor>
<entityTabuSize>7</entityTabuSize>
<valueTabuSize>3</valueTabuSize>
</acceptor>
If you pick a too small tabu size, your solver can still get stuck in a local optimum. On the other hand, with the exception of solution tabu, if you pick a too large tabu size, your solver can get stuck by bouncing of the walls. Use the Benchmarker to fine tweak your configuration.
Simulated Annealing evaluates only a few moves per step, so it steps quickly. In the classic implementation, the first accepted move is the winning step. A move is accepted if it doesn't decrease the score or - in case it does decrease the score - if passes a random check. The chance that a decreasing move passes the random check decreases relative to the size of the score decrement and the time the phase has been running (which is represented as the temperature).
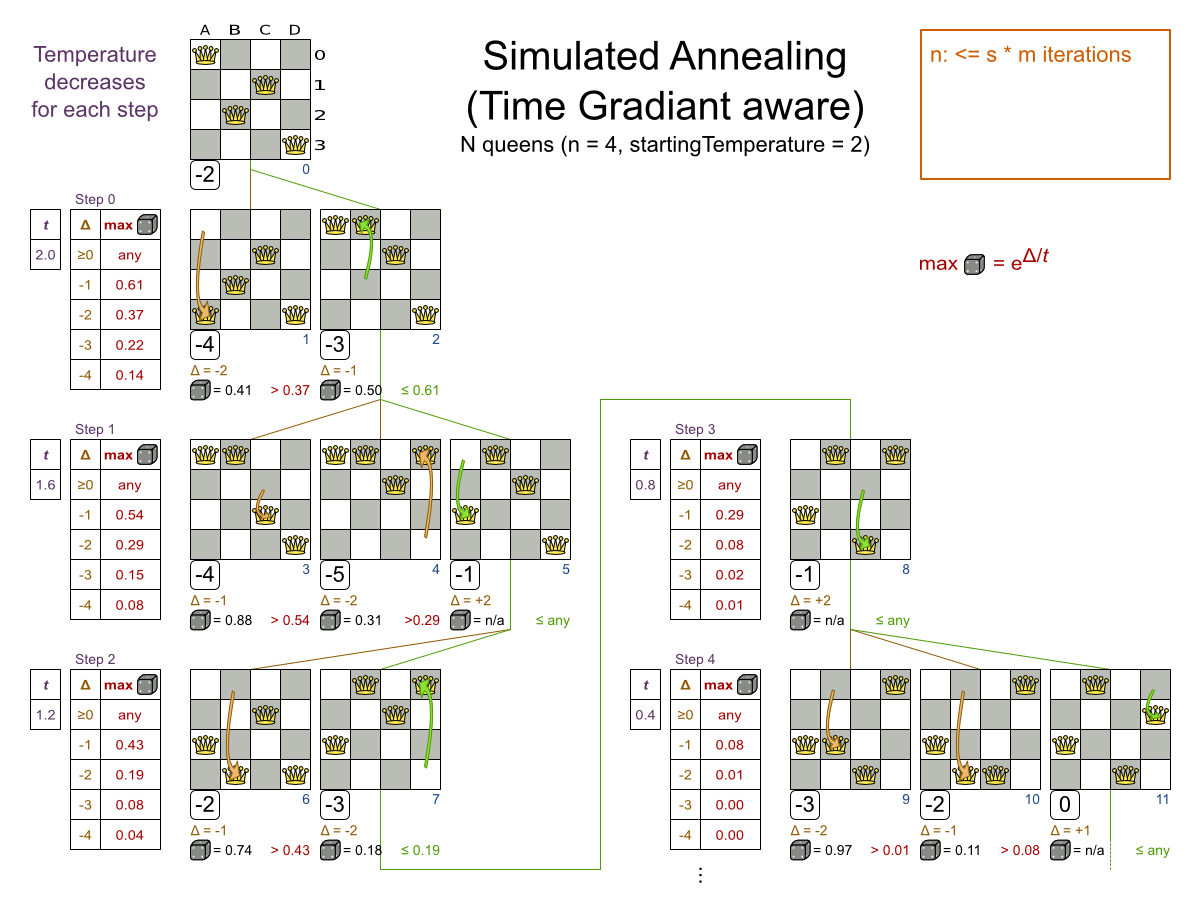
Simulated Annealing does not always pick the move with the highest score, neither does it evaluate many
moves per step. At least at first. Instead, it gives non improving moves also a chance to be picked, depending on
its score and the time gradient of the Termination. In the end, it gradually turns into Hill
Climbing, only accepting improving moves.
Start with a simulatedAnnealingStartingTemperature set to the maximum score delta a
single move can cause. Use the Benchmarker to tweak the
value.
<localSearch>
...
<acceptor>
<simulatedAnnealingStartingTemperature>2hard/100soft</simulatedAnnealingStartingTemperature>
</acceptor>
<forager>
<acceptedCountLimit>1</acceptedCountLimit>
</forager>
</localSearch>
Simulated Annealing should use a low acceptedCountLimit. The classic algorithm uses an
acceptedCountLimit of 1, but often 4 performs
better.
You can even combine it with a tabu acceptor at the same time. That gives Simulated Annealing salted with a bit of Tabu. Use a lower tabu size than in a pure Tabu Search configuration.
<localSearch>
...
<acceptor>
<simulatedAnnealingStartingTemperature>2hard/100soft</simulatedAnnealingStartingTemperature>
<entityTabuSize>5</entityTabuSize>
</acceptor>
<forager>
<acceptedCountLimit>1</acceptedCountLimit>
</forager>
</localSearch>
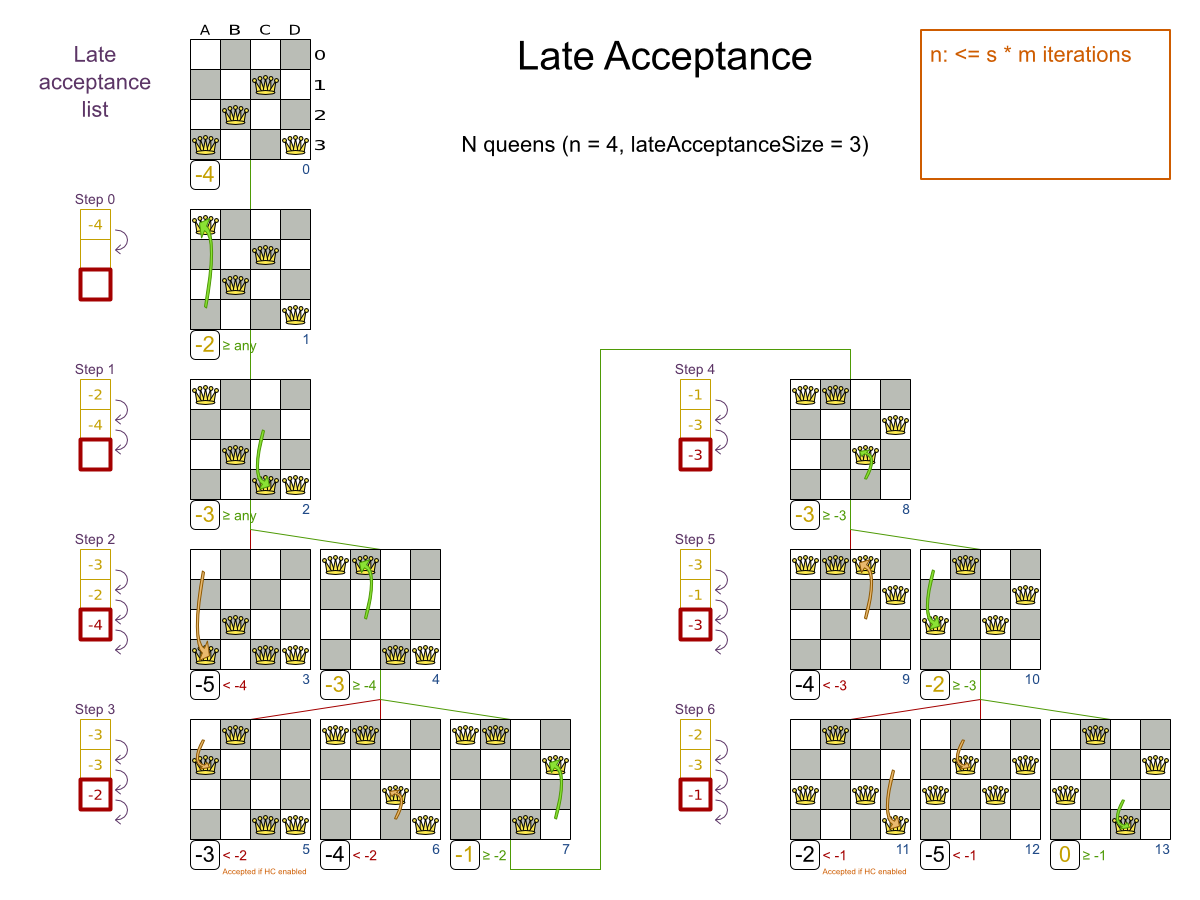
Late Acceptance (also known as Late Acceptance Hill Climbing) also evaluates only a few moves per step. A move is accepted if does not decrease the score, or if it leads to a score that is at least the late score (which is the winning score of a fixed number of steps ago).
Scientific paper: The Late Acceptance Hill-Climbing Heuristic by Edmund K. Burke, Yuri Bykov (2012)
Late Acceptance accepts any move that has a score which is higher than the best score of a number of steps
ago. That number of steps is the lateAcceptanceSize.
<localSearch>
...
<acceptor>
<lateAcceptanceSize>400</lateAcceptanceSize>
</acceptor>
<forager>
<acceptedCountLimit>1</acceptedCountLimit>
</forager>
</localSearch>
You can even combine it with a tabu acceptor at the same time. That gives Late Acceptance salted with a bit of Tabu. Use a lower tabu size than in a pure Tabu Search configuration.
<localSearch>
...
<acceptor>
<lateAcceptanceSize>400</lateAcceptanceSize>
<entityTabuSize>5</entityTabuSize>
</acceptor>
<forager>
<acceptedCountLimit>1</acceptedCountLimit>
</forager>
</localSearch>
Late Acceptance should use a low acceptedCountLimit.
Step Counting Hill Climbing also evaluates only a few moves per step. For a number of steps, it keeps the step score as a threshold. A move is accepted if does not decrease the score, or if it leads to a score that is at least the threshold score.
Scientific paper: An initial study of a novel Step Counting Hill Climbing heuristic applied to timetabling problems by Yuri Bykov, Sanja Petrovic (2013)
Step Counting Hill Climbing accepts any move that has a score which is higher than a threshold score. Every
number of steps (specified by stepCountingHillClimbingSize), the threshold score is set to the
step score.
<localSearch>
...
<acceptor>
<stepCountingHillClimbingSize>400</stepCountingHillClimbingSize>
</acceptor>
<forager>
<acceptedCountLimit>1</acceptedCountLimit>
</forager>
</localSearch>
You can even combine it with a tabu acceptor at the same time, similar as shown in the Late Acceptance section.
Step Counting Hill Climbing should use a low acceptedCountLimit.
You can plug in a custom Termination, MoveSelector,
EntitySelector, ValueSelector or Acceptor by extending the
abstract class and also the related *Config class.
For example, to use a custom MoveSelector, extend the
AbstractMoveSelector class, extend the MoveSelectorConfig class and configure
it in the solver configuration.
Note
It's not possible to inject a Termination, ... instance directly (to avoid extending a
Config class too) because:
A
SolverFactorycan build multipleSolverinstances, which each require a distinctTermination, ... instance.A solver configuration needs to be serializable to and from XML. This makes benchmarking with
PlannerBenchmarkparticularly easy because you can configure differentSolvervariants in XML.A
Configclass is often easier and clearer to configure. For example:TerminationConfigtranslatesminutesSpentLimitandsecondsSpentLimitintotimeMillisSpentLimit.
If you build a better implementation that's not domain specific, consider contributing it back as a pull request on github: we'll optimize it and take it along in future refactors.