The world constantly changes. The planning facts used to create a solution, might change before or during the execution of that solution. There are 3 types of situations:
Unforeseen fact changes: For example: an employee assigned to a shift calls in sick, an airplane scheduled to take off has a technical delay, one of the machines or vehicles break down, ... Use backup planning.
Unknown long term future facts: For example: The hospital admissions for the next 2 weeks are reliable, but those for week 3 and 4 are less reliable and for week 5 and beyond are not worth planning yet. Use continuous planning.
Constantly changing planning facts: Use real-time planning.
Waiting to start planning - to lower the risk of planning facts changing - usually isn't a good way to deal with that. More CPU time means a better planning solution. An incomplete plan is better than no plan.
Luckily, the optimization algorithms support planning a solution that's already (partially) planned, known as repeated planning.
Backup planning is the technique of adding extra score constraints to create space in the planning for when things go wrong. That creates a backup plan in the plan. For example: try to assign an employee as the spare employee (1 for every 10 shifts at the same time), keep 1 hospital bed open in each department, ...
Then, when things go wrong (one of the employees calls in sick), change the planning facts on the original solution (delete the sick employee leave his/her shifts unassigned) and just restart the planning, starting from that solution, which has a different score now. The construction heuristics will fill in the newly created gaps (probably with the spare employee) and the metaheuristics will even improve it further.
Continuous planning is the technique of planning one or more upcoming planning windows at the same time and repeating that process monthly, weekly, daily or hourly. Because time is infinite, there are infinite future windows, so planning all future windows is impossible. Instead, plan only a fixed number of upcoming planning windows.
Past planning windows are immutable. The first upcoming planning window is considered stable (unlikely to change), while later upcoming planning windows are considered draft (likely to change during the next planning effort). Distant future planning windows are not planned at all.
Past planning windows have only immovable planning entities: the planning entities can no longer be changed (they are unable to move), but some of them are still needed in the score calculation, as they might affect some of the score constraints that apply on the upcoming planning entities. For example: when an employee should not work more than 5 days in a row, he shouldn't work today and tomorrow if he worked the past 4 days already.
Sometimes some planning entities are semi-immovable: they can be changed, but occur a certain score penalty if they differ from their original place. For example: avoid rescheduling hospital beds less than 2 days before the patient arrives (unless it's really worth it), avoid changing the airplane gate during the 2 hours before boarding (unless there is no alternative), ...
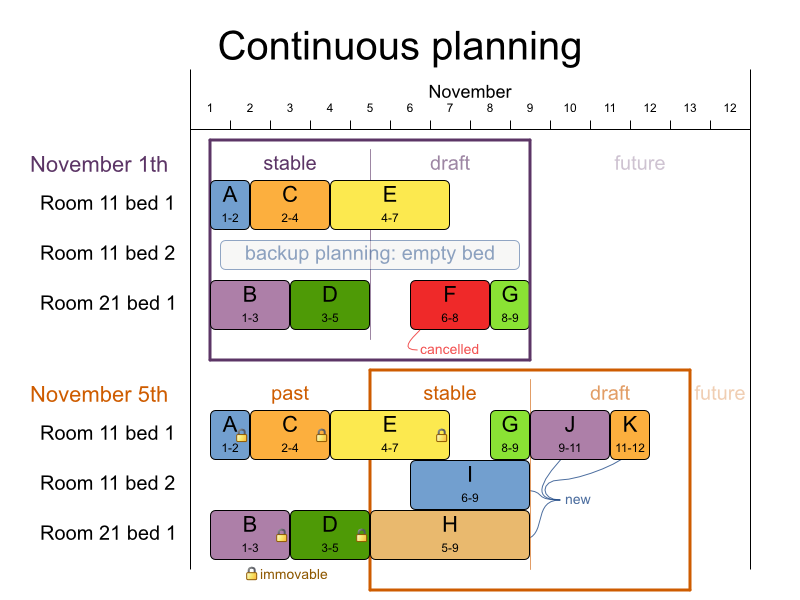
Notice the difference between the original planning of November 1th and the new planning of November 5th: some planning facts (F, H, I, J, K) changed, which results in unrelated planning entities (G) changing too.
To make some planning entities immovable, simply add an entity SelectionFilter that
returns true if an entity is movable and false if it is immovable.
public class MovableShiftAssignmentSelectionFilter implements SelectionFilter<ShiftAssignment> {
public boolean accept(ScoreDirector scoreDirector, ShiftAssignment shiftAssignment) {
ShiftDate shiftDate = shiftAssignment.getShift().getShiftDate();
NurseRoster nurseRoster = (NurseRoster) scoreDirector.getWorkingSolution();
return nurseRoster.getNurseRosterInfo().isInPlanningWindow(shiftDate);
}
}
And configure it like this:
@PlanningEntity(movableEntitySelectionFilter = MovableShiftAssignmentSelectionFilter.class)
public class ShiftAssignment {
...
}
Warning
Custom MoveListFactory and MoveIteratorFactory implementations must
make sure that they don't move immovable entities.
Replanning an existing plan can be very disruptive on the plan. If the plan affects humans (such as employees, drivers, ...), very disruptive changes are often undesirable. In such cases, nonvolatile replanning helps: the gain of changing a plan must be higher than the disruption it causes.

For example, in the Machine Reassignment example, the entity has both the planning variable
machine and its original value originalMachine:
@PlanningEntity(...)
public class ProcessAssignment {
private MrProcess process;
private Machine originalMachine;
private Machine machine;
public Machine getOriginalMachine() {...}
@PlanningVariable(...)
public Machine getMachine() {...}
public boolean isMoved() {
return originalMachine != null && originalMachine != machine;
}
...
}
During planning, the planning variable machine changes. By comparing it with the
originalMachine, a change in plan can be penalized:
rule "processMoved"
when
ProcessAssignment(moved == true)
then
scoreHolder.addSoftConstraintMatch(kcontext, -1000);
endThe soft penalty of -1000 means that a better solution is only accepted if it improves
the soft score for at least 1000 points per variable changed (or if it improves the hard
score).
To do real-time planning, first combine backup planning and continuous planning with short planning windows to lower the burden of real-time planning. As time passes, the problem itself changes:

In the example above, 3 customers are added at different times (07:56,
08:02 and 08:45), after the original customer set finished solving at
07:55 and in some cases after the vehicles already left. OptaPlanner can handle such scenario's
with ProblemFactChange (in combination with immovable
planning entities).
While the Solver is solving, an outside event might want to change one of the problem
facts, for example an airplane is delayed and needs the runway at a later time. Do not change the problem fact
instances used by the Solver while it is solving (from another thread or even in the same
thread), as that will corrupt it. Instead, add a ProblemFactChange to the
Solver which it will execute in the solver thread as soon as possible.
public interface Solver {
...
boolean addProblemFactChange(ProblemFactChange problemFactChange);
boolean isEveryProblemFactChangeProcessed();
...
}
public interface ProblemFactChange {
void doChange(ScoreDirector scoreDirector);
}
Here's an example:
public void deleteComputer(final CloudComputer computer) {
solver.addProblemFactChange(new ProblemFactChange() {
public void doChange(ScoreDirector scoreDirector) {
CloudBalance cloudBalance = (CloudBalance) scoreDirector.getWorkingSolution();
// First remove the planning fact from all planning entities that use it
for (CloudProcess process : cloudBalance.getProcessList()) {
if (ObjectUtils.equals(process.getComputer(), computer)) {
scoreDirector.beforeVariableChanged(process, "computer");
process.setComputer(null);
scoreDirector.afterVariableChanged(process, "computer");
}
}
// A SolutionCloner does not clone problem fact lists (such as computerList)
// Shallow clone the computerList so only workingSolution is affected, not bestSolution or guiSolution
cloudBalance.setComputerList(new ArrayList<CloudComputer>(cloudBalance.getComputerList()));
// Next remove it the planning fact itself
for (Iterator<CloudComputer> it = cloudBalance.getComputerList().iterator(); it.hasNext(); ) {
CloudComputer workingComputer = it.next();
if (ObjectUtils.equals(workingComputer, computer)) {
scoreDirector.beforeProblemFactRemoved(workingComputer);
it.remove(); // remove from list
scoreDirector.beforeProblemFactRemoved(workingComputer);
break;
}
}
}
});
}
Warning
Any change on the problem facts or planning entities in a ProblemFactChange must be
told to the ScoreDirector.
Important
To write a ProblemFactChange correctly, it's important to understand the behaviour of
a planning clone:
Any change in a
ProblemFactChangemust be done on theSolutioninstance ofscoreDirector.getWorkingSolution(). TheworkingSolutionis a planning clone of theBestSolutionChangedEvent'sbestSolution. So theworkingSolutionin theSolveris never the same instance as theSolutionin the rest of your application.A planning clone also clones the planning entities and planning entity collections. So any change on the planning entities must happen on the instances hold by
scoreDirector.getWorkingSolution().A planning clone does not clone the problem facts, nor the problem fact collections. Therefore the
workingSolutionand thebestSolutionshare the same problem fact instances and the same problem fact list instances.Any problem fact or problem fact list changed by a
ProblemFactChangemust be problem cloned first (which can imply rerouting references in other problem facts and planning entities). Otherwise, if theworkingSolutionandbestSolutionare used in different threads (for example a solver thread and a GUI event thread), a race condition can occur.
Note
Many types of changes can leave a planning entity uninitialized, resulting in a partially initialized solution. That's fine, as long as the first solver phase can handle it. All construction heuristics solver phases can handle that, so it's recommended to configure such a solver phase as the first phase.
In essence, the Solver stops, runs the ProblemFactChange and restarts. Each solver phase runs again. This implies the construction heuristic runs again,
but because little or no planning variables are uninitialized (unless you have a nullable planning variable), this doesn't take long.
Each configured phase Termination resets, but each solver Termination (including
terminateEarly) does not reset. Normally however, you won't configure any
Termination, just call Solver.terminateEarly() when the results are needed.
Alternatively, use the daemon mode in combation with BestSolutionChangedEvent as described below.
In real-time planning, it's often useful to have a solver thread wait when it runs out of work, and immediately solve a problem once problem fact changes are added. Putting the Solver in daemon mode has these effects:
If the
Solver'sTerminationterminates, it does not return fromsolve()but waits instead (freeing up CPU).Except for terminateEarly(), which does make it return from
solve(), freeing up system resources (and allowing the application to shutdown gracefully).If a
Solverstarts with an empty planning entity collection, it goes to the waiting state immediately.
If a
ProblemFactChangeis added, it's processed and theSolverruns again.
To configure the daemon mode:
<solver>
<daemon>true</daemon>
...
</solver>
Warning
Don't forget to call Solver.terminateEarly() when your application needs to shutdown to
avoid killing the solver thread unnaturally.
Subscribe to the BestSolutionChangedEvent to
process new best solutions found by the solver thread. A BestSolutionChangedEvent doesn't
guarantee that every ProblemFactChange has been processed already, nor that the solution is
initialized and feasible. To ignore BestSolutionChangedEvents with such invalid solutions, do
this:
public void bestSolutionChanged(BestSolutionChangedEvent<CloudBalance> event) {
// Ignore invalid solutions
if (event.isEveryProblemFactChangeProcessed()
&& event.isNewBestSolutionInitialized()
&& event.getNewBestSolution().getScore().isFeasible()) {
...
}
}