- 6.1. Search Space Size in the Real World
- 6.2. Does Planner Find the Optimal Solution?
- 6.3. Architecture Overview
- 6.4. Optimization Algorithms Overview
- 6.5. Which Optimization Algorithms Should I Use?
- 6.6. Power tweaking or default parameter values
- 6.7. Solver Phase
- 6.8. Scope Overview
- 6.9. Termination
- 6.9.1. TimeMillisSpentTermination
- 6.9.2. UnimprovedTimeMillisSpentTermination
- 6.9.3. BestScoreTermination
- 6.9.4. BestScoreFeasibleTermination
- 6.9.5. StepCountTermination
- 6.9.6. UnimprovedStepCountTermination
- 6.9.7. ScoreCalculationCountTermination
- 6.9.8. Combining Multiple Terminations
- 6.9.9. Asynchronous Termination from Another Thread
- 6.10. SolverEventListener
- 6.11. Custom Solver Phase
The number of possible solutions for a planning problem can be mind blowing. For example:
4 queens has
256possible solutions (4^4) and 2 optimal solutions.5 queens has
3125possible solutions (5^5) and 1 optimal solution.8 queens has
16777216possible solutions (8^8) and 92 optimal solutions.64 queens has more than
10^115possible solutions (64^64).Most real-life planning problems have an incredible number of possible solutions and only 1 or a few optimal solutions.
For comparison: the minimal number of atoms in the known universe (10^80). As a planning problem gets bigger, the search space tends to blow up really fast. Adding only 1 extra planning entity or planning value can heavily multiply the running time of some algorithms.
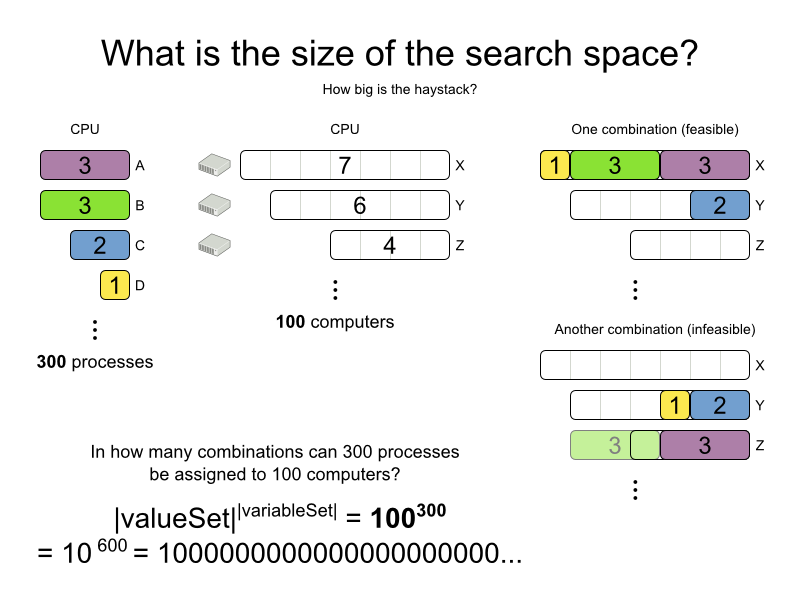
Calculating the number of possible solutions depends on the design of the domain model:
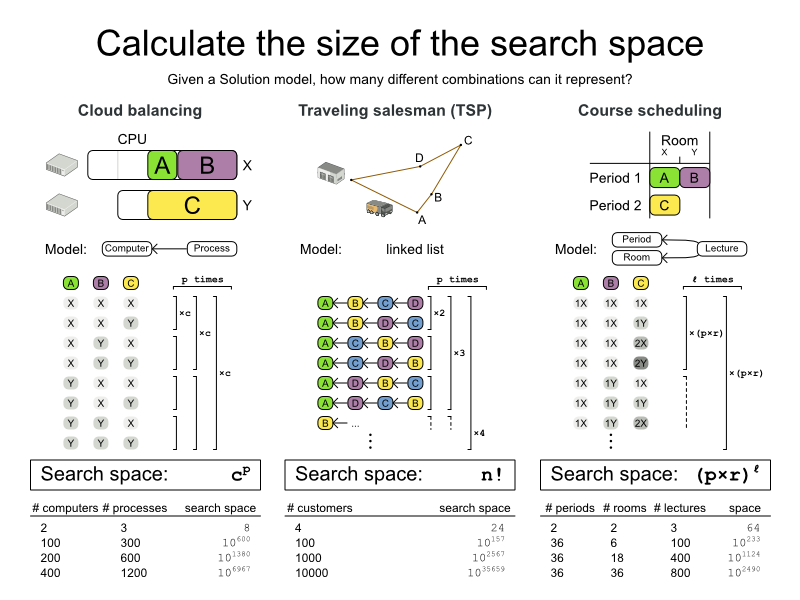
Note
This search space size calculation includes infeasible solutions (if they can be represented by the model), because:
The optimal solution might be infeasible.
There are many types of hard constraints which cannot be incorporated in the formula practically. For example in Cloud Balancing, try incorporating the CPU capacity constraint in the formula.
Even in cases were adding some of the hard constraints in the formula is practical, for example Course Scheduling, the resulting search space is still huge.
An algorithm that checks every possible solution (even with pruning such as in Branch And Bound) can easily run for billions of years on a single real-life planning problem. What we really want is to find the best solution in the limited time at our disposal. Planning competitions (such as the International Timetabling Competition) show that Local Search variations (Tabu Search, Simulated Annealing, Late Acceptance, ...) usually perform best for real-world problems given real-world time limitations.
The business wants the optimal solution, but they also have other requirements:
Scale out: Large production datasets must not crash and have good results too.
Optimize the right problem: The constraints must match the actual business needs.
Available time: The solution must be found in time, before it becomes useless to execute.
Reliability: Every dataset must have at least a decent result (better than a human planner).
Given these requirements, and despite the promises of some salesmen, it's usually impossible for anyone or anything to find the optimal solution. Therefore, Planner focuses on finding the best solution in available time. In realistic, independent competitions, it often comes out as the best reusable software.
The nature of NP-complete problems make scaling a prime concern. The result quality of a small dataset guarantees nothing about the result quality of a large dataset. Scaling issues cannot be mitigated by hardware purchases later on. Start testing with a production sized dataset as soon as possible. Don't assess quality on small datasets (unless production encounters only such datasets). Instead, solve a production sized dataset and compare the results of longer executions, different algorithms and - if available - the human planner.
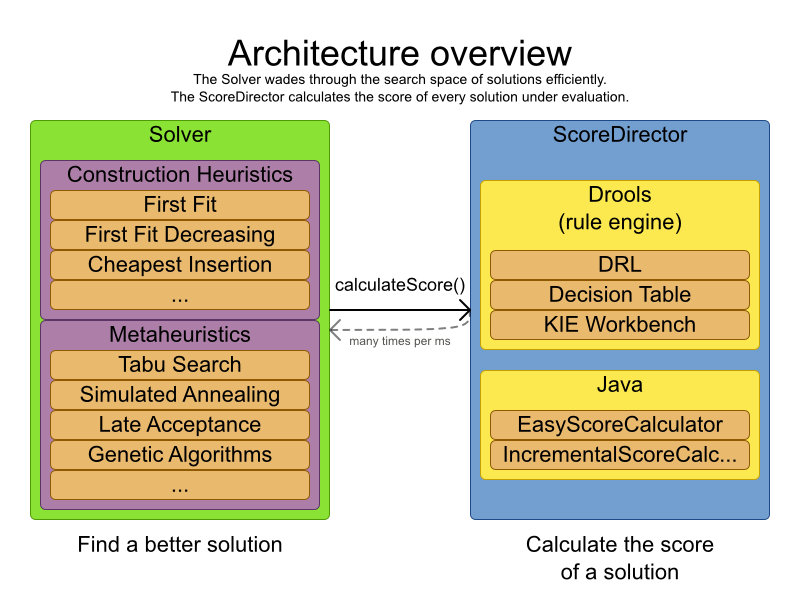
Planner is the first framework to combine optimization algorithms (metaheuristics, ...) with score calculation by a rule engine (such as Drools Expert). This combination turns out to be a very efficient, because:
A rule engine such as Drools Expert is great for calculating the score of a solution of a planning problem. It makes it easy and scalable to add additional soft or hard constraints such as "a teacher shouldn't teach more then 7 hours a day". It does delta based score calculation without any extra code. However it tends to be not suitable to actually find new solutions.
An optimization algorithm is great at finding new improving solutions for a planning problem, without necessarily brute-forcing every possibility. However it needs to know the score of a solution and offers no support in calculating that score efficiently.
Planner supports 3 families of optimization algorithms: Exhaustive Search, Construction Heuristics and Metaheuristics. In practice, Metaheuristics (in combination with Construction Heuristics to initialize) are the recommended choice:
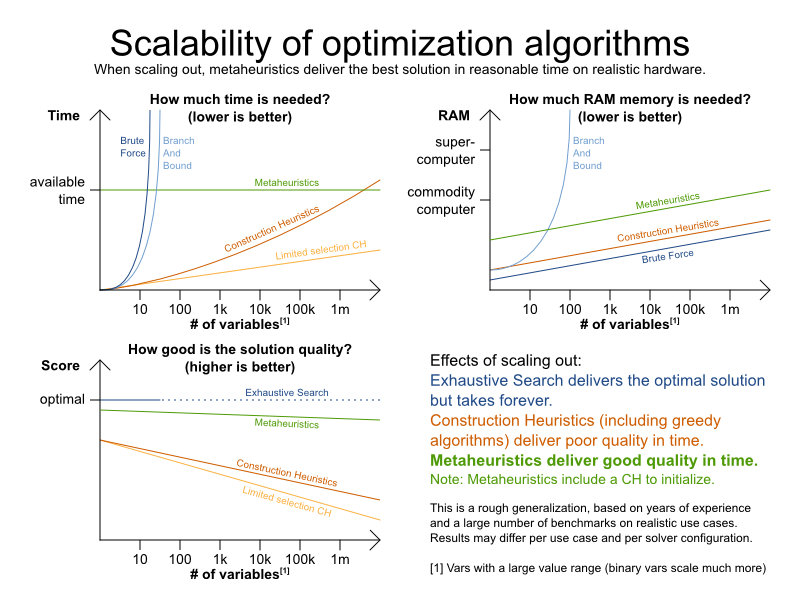
Each of these families of algorithms has multiple optimization algorithms:
Table 6.1. Optimization Algorithms Overview
| Algorithm | Scalable? | Optimal? | Easy to use? | Tweakable? | Requires CH? |
|---|---|---|---|---|---|
| Exhaustive Search (ES) | |||||
| Brute Force | 0/5 | 5/5 | 5/5 | 0/5 | No |
| Branch And Bound | 0/5 | 5/5 | 4/5 | 2/5 | No |
| Construction heuristics (CH) | |||||
| First Fit | 5/5 | 1/5 | 5/5 | 1/5 | No |
| First Fit Decreasing | 5/5 | 2/5 | 4/5 | 2/5 | No |
| Weakest Fit | 5/5 | 2/5 | 4/5 | 2/5 | No |
| Weakest Fit Decreasing | 5/5 | 2/5 | 4/5 | 2/5 | No |
| Strongest Fit | 5/5 | 2/5 | 4/5 | 2/5 | No |
| Strongest Fit Decreasing | 5/5 | 2/5 | 4/5 | 2/5 | No |
| Cheapest Insertion | 3/5 | 2/5 | 5/5 | 2/5 | No |
| Regret Insertion | 3/5 | 2/5 | 5/5 | 2/5 | No |
| Metaheuristics (MH) | |||||
| Local Search | |||||
| Hill Climbing | 5/5 | 2/5 | 4/5 | 3/5 | Yes |
| Tabu Search | 5/5 | 4/5 | 3/5 | 5/5 | Yes |
| Simulated Annealing | 5/5 | 4/5 | 2/5 | 5/5 | Yes |
| Late Acceptance | 5/5 | 4/5 | 3/5 | 5/5 | Yes |
| Step Counting Hill Climbing | 5/5 | 4/5 | 3/5 | 5/5 | Yes |
| Evolutionary Algorithms | |||||
| Evolutionary Strategies | 4/5 | 3/5 | 2/5 | 5/5 | Yes |
| Genetic Algorithms | 4/5 | 3/5 | 2/5 | 5/5 | Yes |
If you want to learn more about metaheuristics, read the free books Essentials of Metaheuristics or Clever Algorithms.
The best optimization algorithms configuration for your use case depends heavily on your use case. Nevertheless, this vanilla recipe will get you into the game with a pretty good configuration, probably much better than what you're used to.
Start with a quick configuration that involves little or no configuration and optimization code:
Next, implement planning entity difficulty comparison and turn it into:
Next, add Late Acceptance behind it:
First Fit Decreasing
Late Acceptance. A Late Acceptance size of 400 usually works well.
At this point the free lunch is over. The return on invested time lowers. The result is probably already more than good enough.
But you can do even better, at a lower return on invested time. Use the Benchmarker and try a couple of different Tabu Search, Simulated Annealing and Late Acceptance configurations, for example:
First Fit Decreasing
Tabu Search. An entity tabu size of 7 usually works well.
Use the Benchmarker to improve the values for those size parameters.
If it's worth your time, continue experimenting further. For example, try combining multiple algorithms together:
First Fit Decreasing
Late Acceptance (relatively long time)
Tabu Search (relatively short time)
Many optimization algorithms have parameters which affect results and scalability. Planner applies configuration by exception, so all optimization algorithms have default parameter values. This is very similar to the Garbage Collection parameters in a JVM: most users have no need to tweak them, but power users do tweak them.
The default parameter values are good enough for many cases (and especially for prototypes), but if development time allows, it can be well worth to power tweak them with the benchmarker for better results and scalability on a specific use case. The documentation for each optimization algorithm also declares its advanced configuration for power tweaking.
Warning
The default value of parameters will change between minor versions, to improve them for most users (but not necessary for you). To shield yourself from these changes, for better or worse, always use the advanced configuration. This is not recommended.
A Solver can use multiple optimization algorithms in sequence. Each
optimization algorithm is represented by a solver Phase. There is never more than 1
Phase solving at the same time.
Note
Some Phase implementations can combine techniques from multiple optimization algorithms,
but it is still just 1 Phase. For example: a Local Search Phase can do
Simulated Annealing with entity Tabu.
Here's a configuration that runs 3 phases in sequence:
<solver>
...
<constructionHeuristic>
... <!-- First phase: First Fit Decreasing -->
</constructionHeuristic>
<localSearch>
... <!-- Second phase: Late Acceptance -->
</localSearch>
<localSearch>
... <!-- Third phase: Tabu Search -->
</localSearch>
</solver>The solver phases are run in the order defined by solver configuration. When the first
Phase terminates, the second Phase starts, and so on. When the last
Phase terminates, the Solver terminates. Usually, a Solver
will first run a construction heuristic and then run 1 or multiple metaheuristics:
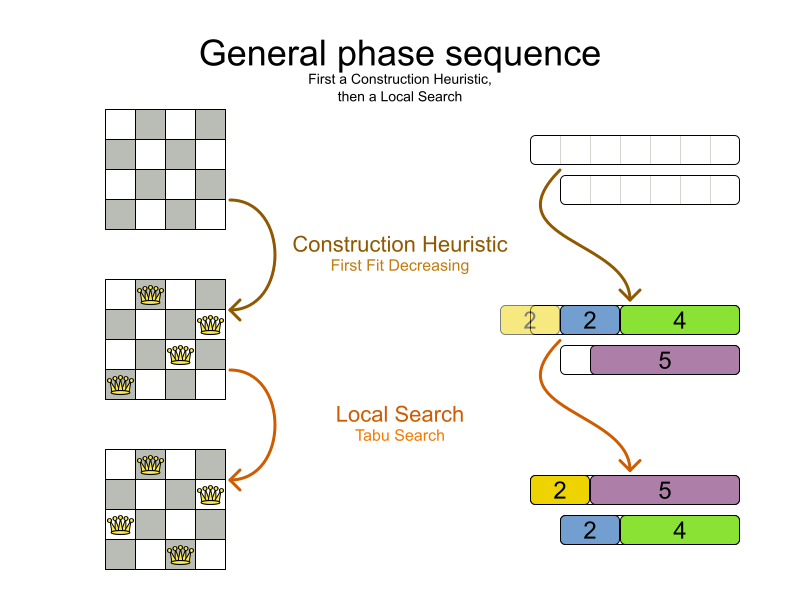
If no phases are configured, Planner will default to a Construction Heuristic phase followed by a Local Search phase.
Some phases (especially construction heuristics) will terminate automatically. Other phases (especially
metaheuristics) will only terminate if the Phase is configured to terminate:
<solver>
...
<termination><!-- Solver termination -->
<secondsSpentLimit>90</secondsSpentLimit>
</termination>
<localSearch>
<termination><!-- Phase termination -->
<secondsSpentLimit>60</secondsSpentLimit><!-- Give the next phase a chance to run too, before the Solver terminates -->
</termination>
...
</localSearch>
<localSearch>
...
</localSearch>
</solver>If the Solver terminates (before the last Phase terminates itself), the
current phase is terminated and all subsequent phases won't run.
A solver will iteratively run phases. Each phase will usually iteratively run steps. Each step, in turn, usually iteratively runs moves. These form 4 nested scopes: solver, phase, step and move.
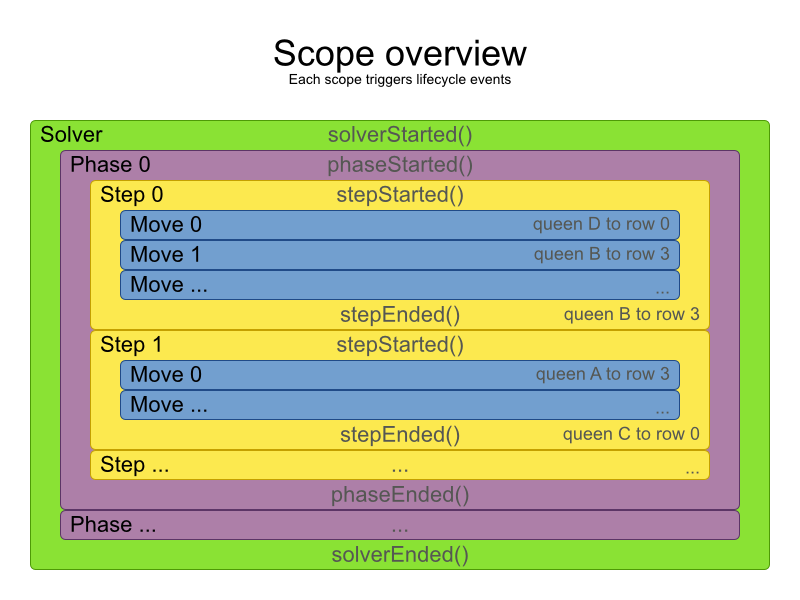
Configure logging to display the log messages of each scope.
Not all phases terminate automatically and sometimes you don't want to wait that long anyway. A
Solver can be terminated synchronously by up-front configuration or asynchronously from another
thread.
Especially metaheuristic phases will need to be told when to stop solving. This can be because of a number of reasons: the time is up, the perfect score has been reached, just before its solution is used, ... The only thing you can't depend on, is on finding the optimal solution (unless you know the optimal score), because a metaheuristic algorithm generally doesn't know it when it finds the optimal solution. For real-life problems this doesn't turn out to be much of a problem, because finding the optimal solution could take years, so you'll want to terminate sooner anyway. The only thing that matters is finding the best solution in the available time.
Important
If no termination is configured (and a metaheuristic algorithm is used), the Solver will
run forever, until terminateEarly() is called from another thread.
This is especially common during real-time planning.
For synchronous termination, configure a Termination on a Solver or a
Phase when it needs to stop. You can implement your own Termination, but the
built-in implementations should suffice for most needs. Every Termination can calculate a
time gradient (needed for some optimization algorithms), which is a ratio between the time
already spent solving and the estimated entire solving time of the Solver or
Phase.
Terminates when an amount of time has been used.
<termination>
<millisecondsSpentLimit>500</millisecondsSpentLimit>
</termination> <termination>
<secondsSpentLimit>10</secondsSpentLimit>
</termination> <termination>
<minutesSpentLimit>5</minutesSpentLimit>
</termination> <termination>
<hoursSpentLimit>1</hoursSpentLimit>
</termination> <termination>
<daysSpentLimit>2</daysSpentLimit>
</termination>Multiple time types can be used together, for example to configure 150 minutes, either configure it directly:
<termination>
<minutesSpentLimit>150</minutesSpentLimit>
</termination>Or use a combination that sums up to 150 minutes:
<termination>
<hoursSpentLimit>2</hoursSpentLimit>
<minutesSpentLimit>30</minutesSpentLimit>
</termination>Note
This Termination will most likely sacrifice perfect reproducibility (even with
environmentMode REPRODUCIBLE) because the available CPU time differs
frequently between runs:
The available CPU time influences the number of steps that can be taken, which might be a few more or less.
The
Terminationmight produce slightly different time gradient values, which will send time gradient based algorithms (such as Simulated Annealing) on a radically different path.
Terminates when the best score hasn't improved in an amount of time.
<localSearch>
<termination>
<unimprovedMillisecondsSpentLimit>500</unimprovedMillisecondsSpentLimit>
</termination>
</localSearch> <localSearch>
<termination>
<unimprovedSecondsSpentLimit>10</unimprovedSecondsSpentLimit>
</termination>
</localSearch> <localSearch>
<termination>
<unimprovedMinutesSpentLimit>5</unimprovedMinutesSpentLimit>
</termination>
</localSearch> <localSearch>
<termination>
<unimprovedHoursSpentLimit>1</unimprovedHoursSpentLimit>
</termination>
</localSearch> <localSearch>
<termination>
<unimprovedDaysSpentLimit>1</unimprovedDaysSpentLimit>
</termination>
</localSearch>This termination should not be applied to Construction Heuristics, because they only update the best
solution at the end. Therefore it might be better to configure it on a specific Phase (such as
<localSearch>), instead of on the Solver itself.
Note
This Termination will most likely sacrifice perfect reproducibility (even with
environmentMode REPRODUCIBLE) because the available CPU time differs
frequently between runs:
The available CPU time influences the number of steps that can be taken, which might be a few more or less.
The
Terminationmight produce slightly different time gradient values, which will send time gradient based algorithms (such as Simulated Annealing) on a radically different path.
Terminates when a certain score has been reached. Use this Termination if you know the
perfect score, for example for 4 queens (which uses a SimpleScore):
<termination>
<bestScoreLimit>0</bestScoreLimit>
</termination>For a planning problem with a HardSoftScore, it could look like this:
<termination>
<bestScoreLimit>0hard/-5000soft</bestScoreLimit>
</termination>For a planning problem with a BendableScore with 3 hard levels and 1 soft level, it could look like this:
<termination>
<bestScoreLimit>[0/0/0]hard/[-5000]soft</bestScoreLimit>
</termination>To terminate once a feasible solution has been reached, this Termination isn't practical
because it requires a bestScoreLimit such as 0hard/-2147483648soft. Instead,
use the next termination.
Terminates when a certain score is feasible. Requires that the Score implementation
implements FeasibilityScore.
<termination>
<bestScoreFeasible>true</bestScoreFeasible>
</termination>This Termination is usually combined with other terminations.
Terminates when a number of steps has been reached. This is useful for hardware performance independent runs.
<localSearch>
<termination>
<stepCountLimit>100</stepCountLimit>
</termination>
</localSearch>This Termination can only be used for a Phase (such as
<localSearch>), not for the Solver itself.
Terminates when the best score hasn't improved in a number of steps. This is useful for hardware performance independent runs.
<localSearch>
<termination>
<unimprovedStepCountLimit>100</unimprovedStepCountLimit>
</termination>
</localSearch>If the score hasn't improved recently, it's probably not going to improve soon anyway and it's not worth the effort to continue. We have observed that once a new best solution is found (even after a long time of no improvement on the best solution), the next few steps tend to improve the best solution too.
This Termination can only be used for a Phase (such as
<localSearch>), not for the Solver itself.
Terminates when a number of score calculations have been reached. That's usually the sum of the number of moves and the number of steps. This is useful for benchmarking.
<termination>
<scoreCalculationCountLimit>100000</scoreCalculationCountLimit>
</termination>Switching EnvironmentMode can heavily impact when this termination ends.
Terminations can be combined, for example: terminate after 100 steps or if a score of
0 has been reached:
<termination>
<terminationCompositionStyle>OR</terminationCompositionStyle>
<stepCountLimit>100</stepCountLimit>
<bestScoreLimit>0</bestScoreLimit>
</termination>Alternatively you can use AND, for example: terminate after reaching a feasible score of at least
-100 and no improvements in 5 steps:
<termination>
<terminationCompositionStyle>AND</terminationCompositionStyle>
<unimprovedStepCountLimit>5</unimprovedStepCountLimit>
<bestScoreLimit>-100</bestScoreLimit>
</termination>This example ensures it doesn't just terminate after finding a feasible solution, but also completes any obvious improvements on that solution before terminating.
Sometimes you'll want to terminate a Solver early from another thread, for example because a user action or
a server restart. This cannot be configured by a Termination as it's impossible to predict when
and if it will occur. Therefore the Solver interface has these 2 thread-safe methods:
public interface Solver<Solution_> {
...
boolean terminateEarly();
boolean isTerminateEarly();
}If you call the terminateEarly() method from another thread, the
Solver will terminate at its earliest convenience and the solve(Solution)
method will return (in the original Solver thread).
Note
Interrupting the Solver thread (which is the thread that called Solver.solve(Solution))
has the same affect as calling terminateEarly() except that it leaves that thread in the
interrupted state. This guarantees a graceful shutdown when an ExecutorService (such as a
thread pool) is shutdown because that only interrupts all active threads in the pool.
Each time a new best solution is found, the Solver fires a
BestSolutionChangedEvent, in the solver's thread.
To listen to such events, add a SolverEventListener to the
Solver:
public interface Solver<Solution_> {
...
void addEventListener(SolverEventListener<S> eventListener);
void removeEventListener(SolverEventListener<S> eventListener);
}The BestSolutionChangedEvent's newBestSolution might not be initialized
or feasible. Use the isFeasible() method on BestSolutionChangedEvent's new
best Score to detect such cases:
solver.addEventListener(new SolverEventListener<CloudBalance>() {
public void bestSolutionChanged(BestSolutionChangedEvent<CloudBalance> event) {
// Ignore infeasible (including uninitialized) solutions
if (event.getNewBestSolution().getScore().isFeasible()) {
...
}
}
});Use Score.isSolutionInitialized() instead of Score.isFeasible() to only
ignore uninitialized solutions, but do accept infeasible solutions too.
Warning
The bestSolutionChanged() method is called in the solver's thread, as part of
Solver.solve(). So it should return quickly to avoid slowing down the solving.
Between phases or before the first phase, you might want to run a custom optmization algorithm to initialize
the Solution or to take some low hanging fruit to get a better score quickly. Yet you'll still
want to reuse the score calculation. For example, to implement a custom Construction Heuristic without implementing
an entire Phase.
Note
Most of the time, a custom solver phase is not worth the hassle. The supported Constructions Heuristics are configurable (use the Benchmarker to tweak them), Termination aware and support
partially initialized solutions too.
The CustomPhaseCommand interface looks like this:
public interface CustomPhaseCommand<Solution_> {
...
void changeWorkingSolution(ScoreDirector<Solution_> scoreDirector);
}For example, extend AbstractCustomPhaseCommand and implement the
changeWorkingSolution() method:
public class ToOriginalMachineSolutionInitializer extends AbstractCustomPhaseCommand<MachineReassignment> {
public void changeWorkingSolution(ScoreDirector<MachineReassignment> scoreDirector) {
MachineReassignment machineReassignment = scoreDirector.getWorkingSolution();
for (MrProcessAssignment processAssignment : machineReassignment.getProcessAssignmentList()) {
scoreDirector.beforeVariableChanged(processAssignment, "machine");
processAssignment.setMachine(processAssignment.getOriginalMachine());
scoreDirector.afterVariableChanged(processAssignment, "machine");
scoreDirector.triggerVariableListeners();
}
}
}Warning
Any change on the planning entities in a CustomPhaseCommand must be notified to the
ScoreDirector.
Warning
Do not change any of the problem facts in a CustomPhaseCommand. That will corrupt the
Solver because any previous score or solution was for a different problem. To do that, read
about repeated planning and do it with a ProblemFactChange instead.
Configure your CustomPhaseCommand like this:
<solver>
...
<customPhase>
<customPhaseCommandClass>org.optaplanner.examples.machinereassignment.solver.solution.initializer.ToOriginalMachineSolutionInitializer</customPhaseCommandClass>
</customPhase>
... <!-- Other phases -->
</solver>Configure multiple customPhaseCommandClass instances to run them in sequence.
Important
If the changes of a CustomPhaseCommand don't result in a better score, the best solution
won't be changed (so effectively nothing will have changed for the next Phase or
CustomPhaseCommand). To force such changes anyway, use
forceUpdateBestSolution:
<customPhase>
<customPhaseCommandClass>...MyUninitializer</customPhaseCommandClass>
<forceUpdateBestSolution>true</forceUpdateBestSolution>
</customPhase>Note
If the Solver or a Phase wants to terminate while a
CustomPhaseCommand is still running, it will wait to terminate until the
CustomPhaseCommand is done, however long that takes. The build-in solver phases don't suffer
from this problem.
To configure values of your CustomPhaseCommand dynamically in the solver configuration (so
you can tweak those parameters with the Benchmarker), use the
customProperties element:
<customPhase>
<customProperties>
<mySelectionSize>5</mySelectionSize>
</customProperties>
</customPhase>Then override the applyCustomProperties() method to parse and apply them when a
Solver is build.
public class MySolutionInitializer extends AbstractCustomPhaseCommand<MySolution> {
private int mySelectionSize;
public void applyCustomProperties(Map<String, String> customPropertyMap) {
String mySelectionSizeString = customPropertyMap.get("mySelectionSize");
if (mySelectionSizeString == null) {
throw new IllegalArgumentException("A customProperty (mySelectionSize) is missing from the solver configuration.");
}
solverFactory = SolverFactory.createFromXmlResource(partitionSolverConfigResource);
if (customPropertyMap.size() != 1) {
throw new IllegalArgumentException("The customPropertyMap's size (" + customPropertyMap.size() + ") is not 1.");
}
mySelectionSize = Integer.parseInt(mySelectionSizeString);
}
...
}