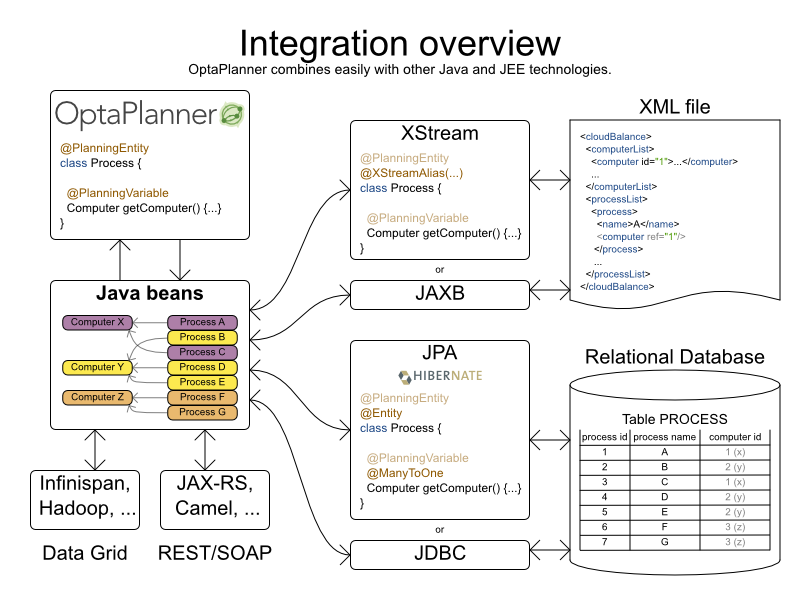
Planner's input and output data (the planning problem and the best solution) are plain old JavaBeans (POJO's), so integration with other Java technologies is straightforward. For example:
To read a planning problem from the database (and store the best solution in it), annotate the domain POJO's with JPA annotations.
To read a planning problem from an XML file (and store the best solution in it), annotate the domain POJO's with XStream or JAXB annotations.
To expose the Solver as a REST Service that reads the planning problem and responds with the best solution, annotate the domain POJO's with XStream, JAXB or Jackson annotations and hook the
Solverin Camel or RESTEasy.
Enrich the domain POJO's (solution, entities and problem facts) with JPA annotations to store them in a database.
Note
Do not confuse JPA's @Entity annotation with Planner's
@PlanningEntity annotation. They can appear both on the same class:
@PlanningEntity // OptaPlanner annotation
@Entity // JPA annotation
public class Talk {...}Add a dependency to the optaplanner-persistence-jpa jar to take advantage of these extra
integration features:
When a Score is persisted into a relational database, JPA and Hibernate will default to
Java serializing it to a BLOB column. This has several disadvantages:
The Java serialization format of
Scoreclasses is currently not backwards compatible. Upgrading to a newer Planner version can break reading an existing database.The score is not easily readable for a query executed in the database console. This is annoying during development.
The score cannot be used in a SQL or JPA-QL query to efficiently filter the results: for example to query all infeasible schedules.
To avoid these issues, configure it to instead use INTEGER (or other) columns, by using the appropriate
*ScoreHibernateType for your Score type, for example for a
HardSoftScore:
@PlanningSolution
@Entity
@TypeDef(defaultForType = HardSoftScore.class, typeClass = HardSoftScoreHibernateType.class)
public class CloudBalance {
@PlanningScore
@Columns(columns = {@Column(name = "initScore"), @Column(name = "hardScore"), @Column(name = "softScore")})
protected HardSoftScore score;
...
}Note
Configure the same number of @Column annotations as the number of score levels in the
score plus one (for the initScore), otherwise Hibernate will fail fast because a property
mapping has the wrong number of columns.
In this case, the DDL will look like this:
CREATE TABLE CloudBalance(
...
initScore INTEGER,
hardScore INTEGER,
softScore INTEGER
);When using a BigDecimal based Score, specify the precision and scale
of the columns to avoid silent rounding:
@PlanningSolution
@Entity
@TypeDef(defaultForType = HardSoftBigDecimalScore.class, typeClass = HardSoftBigDecimalScoreHibernateType.class)
public class CloudBalance{
@PlanningScore
@Columns(columns = {
@Column(name = "initScore")
@Column(name = "hardScore", precision = 10, scale = 5),
@Column(name = "softScore", precision = 10, scale = 5)})
protected HardSoftBigDecimalScore score;
...
}In this case, the DDL will look like this:
CREATE TABLE CloudBalance(
...
initScore INTEGER,
hardScore DECIMAL(10, 5),
softScore DECIMAL(10, 5)
);When using any type of bendable Score, specify the hard and soft level sizes as
parameters:
@PlanningSolution
@Entity
@TypeDef(defaultForType = BendableScore.class, typeClass = BendableScoreHibernateType.class, parameters = {
@Parameter(name = "hardLevelsSize", value = "3"),
@Parameter(name = "softLevelsSize", value = "2")})
public class Schedule {
@PlanningScore
@Columns(columns = {
@Column(name = "initScore")
@Column(name = "hard0Score"),
@Column(name = "hard1Score"),
@Column(name = "hard2Score"),
@Column(name = "soft0Score"),
@Column(name = "soft1Score")})
protected BendableScore score;
...
}All this support is Hibernate specific because currently JPA 2.1's converters do not support converting to multiple columns.
In JPA and Hibernate, there is usually a @ManyToOne relationship from most problem fact
classes to the planning solution class. Therefore, the problem fact classes reference the planning solution
class, which implies that when the solution is planning cloned, they
need to be cloned too. Use an @DeepPlanningClone on each such problem fact class to enforce
that:
@PlanningSolution // OptaPlanner annotation
@Entity // JPA annotation
public class Conference {
@OneToMany(mappedBy="conference")
private List<Room> roomList;
...
}@DeepPlanningClone // OptaPlanner annotation: Force the default planning cloner to planning clone this class too
@Entity // JPA annotation
public class Room {
@ManyToOne
private Conference conference; // Because of this reference, this problem fact needs to be planning cloned too
}Neglecting to do this can lead to persisting duplicate solutions, JPA exceptions or other side effects.
Enrich the domain POJO's (solution, entities and problem facts) with XStream annotations to serialize them to/from XML or JSON.
Add a dependency to the optaplanner-persistence-xstream jar to take advantage of these
extra integration features:
When a Score is marshalled to XML or JSON by the default XStream configuration, it's
verbose and ugly. To fix that, configure the appropriate ScoreXStreamConverter:
@PlanningSolution
@XStreamAlias("CloudBalance")
public class CloudBalance {
@PlanningScore
@XStreamConverter(HardSoftScoreXStreamConverter.class)
private HardSoftScore score;
...
}For example, this will generate pretty XML:
<CloudBalance>
...
<score>0hard/-200soft</score>
</CloudBalance>The same applies for a bendable score:
@PlanningSolution
@XStreamAlias("Schedule")
public class Schedule {
@PlanningScore
@XStreamConverter(BendableScoreXStreamConverter.class)
private BendableScore score;
...
}For example, this will generate:
<Schedule>
...
<score>[0/0]hard/[-100/-20/-3]soft</score>
</Schedule>The hardLevelsSize and softLevelsSize implied, when reading a
bendable score from an XML element, must always be in sync with those in the solver.
Enrich the domain POJO's (solution, entities and problem facts) with JAXB annotations to serialize them to/from XML or JSON.
Add a dependency to the optaplanner-persistence-jaxb jar to take advantage of these extra
integration features:
When a Score is marshalled to XML or JSON by the default JAXB configuration, it's
corrupted. To fix that, configure the appropriate ScoreJaxbXmlAdapter:
@PlanningSolution
@XmlRootElement @XmlAccessorType(XmlAccessType.FIELD)
public class CloudBalance {
@PlanningScore
@XmlJavaTypeAdapter(HardSoftScoreJaxbXmlAdapter.class)
private HardSoftScore score;
...
}For example, this will generate pretty XML:
<cloudBalance>
...
<score>0hard/-200soft</score>
</cloudBalance>The same applies for a bendable score:
@PlanningSolution
@XmlRootElement @XmlAccessorType(XmlAccessType.FIELD)
public class Schedule {
@PlanningScore
@XmlJavaTypeAdapter(BendableScoreJaxbXmlAdapter.class)
private BendableScore score;
...
}For example, with a hardLevelsSize of 2 and a
softLevelsSize of 3, that will generate:
<schedule>
...
<score>[0/0]hard/[-100/-20/-3]soft</score>
</schedule>The hardLevelsSize and softLevelsSize implied, when reading a
bendable score from an XML element, must always be in sync with those in the solver.
Enrich the domain POJO's (solution, entities and problem facts) with Jackson annotations to serialize them to/from JSON.
Add a dependency to the optaplanner-persistence-jackson jar to take advantage of these extra
integration features:
When a Score is marshalled to JSON by the default Jackson configuration, it
fails. To fix that, configure a ScoreJacksonJsonSerializer and the appropriate
ScoreJacksonJsonDeserializer:
@PlanningSolution
public class CloudBalance {
@PlanningScore
@JsonSerialize(using = ScoreJacksonJsonSerializer.class)
@JsonDeserialize(using = HardSoftScoreJacksonJsonDeserializer.class)
private HardSoftScore score;
...
}For example, this will generate pretty JSON:
{
...
"score":"0hard/-200soft"
}The same applies for a bendable score:
@PlanningSolution
public class Schedule {
@PlanningScore
@JsonSerialize(using = ScoreJacksonJsonSerializer.class)
@JsonDeserialize(using = BendableScoreJacksonXmlAdapter.class)
private BendableScore score;
...
}For example, with a hardLevelsSize of 2 and a
softLevelsSize of 3, that will generate:
{
...
"score":"[0/0]hard/[-100/-20/-3]soft"
}The hardLevelsSize and softLevelsSize implied, when reading a
bendable score from a JSON element, must always be in sync with those in the solver.
Camel is an enterprise integration framework which includes support for Planner (starting from Camel 2.13). It can expose a use case as a REST service, a SOAP service, a JMS service, ...
Read the documentation for the camel-optaplanner component. That component works in Karaf too.
To deploy an Planner web application on WildFly, simply include the optaplanner dependency jars in the
war file's WEB-INF/lib directory (just like any other dependency) as shown
in the optaplanner-webexamples-*.war. However, in this approach the war file can easily grow to
several MB in size, which is fine for a one-time deployment, but too heavyweight for frequent redeployments
(especially over a slow network connection).
The remedy is to use deliver the optaplanner jars in a JBoss module to WildFly and create a skinny war. Let's create an module called org.optaplanner:
Navigate to the directory
${WILDFLY_HOME}/modules/system/layers/base/. This directory contains the JBoss modules of WildFly. Create directory structureorg/optaplanner/mainfor our new module.Copy
optaplanner-core-${version}.jarand all its direct and transitive dependency jars into that new directory. Use "mvn dependency:tree" on each optaplanner artifact to discover all dependencies.Create the file
module.xmlin that new directory. Give it this content:<?xml version="1.0" encoding="UTF-8"?> <module xmlns="urn:jboss:module:1.3" name="org.optaplanner"> <resources> ... <resource-root path="kie-api-${version}.jar"/> ... <resource-root path="optaplanner-core-${version}.jar"/> ... <resource-root path="."/> </resources> <dependencies> <module name="javaee.api"/> </dependencies> </module>
Navigate to the deployed
warfile.Remove
optaplanner-core-${version}.jarand all its direct and transitive dependency jars from theWEB-INF/libdirectory in thewarfile.Create the file
jboss-deployment-structure.xmlin theWEB-INF/libdirectory. Give it this content:<?xml version="1.0" encoding="UTF-8" ?> <jboss-deployment-structure> <deployment> <dependencies> <module name="org.optaplanner" export="true"/> </dependencies> </deployment> </jboss-deployment-structure>
Because of JBoss Modules' ClassLoader magic, you'll likely need to provide the
ClassLoader of your classes during the SolverFactory
creation, so it can find the classpath resources (such as the solver config, score DRL's and domain
classes) in your jars.
The optaplanner-core jar includes OSGi metadata in its MANIFEST.MF
file to function properly in an OSGi environment too. Furthermore, the maven artifact
drools-karaf-features (which will be renamed to kie-karaf-features) contains
a features.xml file that supports the OSGi-feature
optaplanner-engine.
Because of the OSGi's ClassLoader magic, you'll likely need to provide the
ClassLoader of your classes during the SolverFactory
creation, so it can find the classpath resources (such as the solver config, score DRL's and domain
classes) in your jars.
Note
Planner does not require OSGi. It works perfectly fine in a normal Java environment too.
Android is not a complete JVM (because some JDK libraries are missing), but Planner works on Android with easy Java or incremental Java score calculation. The Drools rule engine does not work on Android yet, so Drools score calculation doesn't work on Android and its dependencies need to be excluded.
Workaround to use Planner on Android:
Add a dependency to the
build.gradlefile in your Android project to excludeorg.droolsandxmlpulldependencies:dependencies { ... compile('org.optaplanner:optaplanner-core:...') { exclude group: 'xmlpull' exclude group: 'org.drools' } ... }
A good Planner implementation beats any good human planner for non-trivial datasets. Many human planners fail to accept this, often because they feel threatened by an automated system.
But despite that, both can benefit if the human planner acts as supervisor to Planner:
The human planner defines and validates the score function.
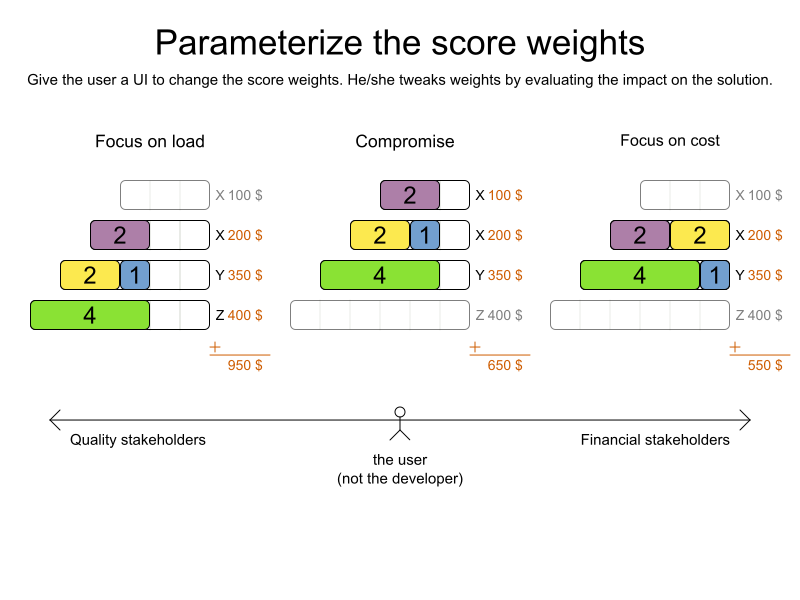
Some examples expose a
*Parametrizationobject, which defines the weight for each score constraint. The human planner can then tweak those weights at runtime.When the business changes, the score function often needs to change too. The human planner can notify the developers to add, change or remove score constraints.
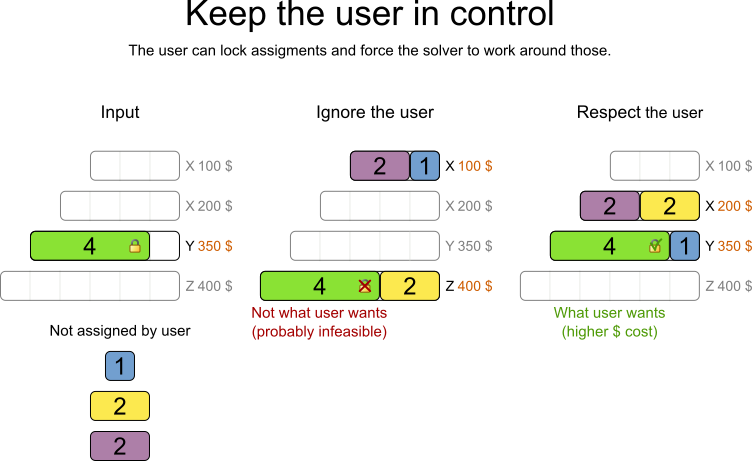
The human planner is always in control of Planner.
As shown in the course scheduling example, the human planner can lock 1 or more planning variables to a specific planning value and make those immovable. Because they are immovable, Planner does not change them: it optimizes the planning around the enforcements made by the human. If the human planner locks all planning variables, he/she sidelines Planner completely.
In a prototype implementation, the human planner might use this occasionally. But as the implementation matures, it must become obsolete. But do keep the feature alive: as a reassurance for the humans. Or in case that one day the business changes dramatically before the score constraints can be adjusted.
Therefore, it's often a good idea to involve the human planner in your project.